YACS¶
L’utilisation de schémas YACS va permettre de coupler un calcul et une adaptation comme il est décrit dans Introduction. Ce couplage peut être répété au sein d’une boucle jusqu’à l’obtention d’un critère de convergence par exemple. Il existe de nombreuses façons de programmer un schéma YACS. La solution proposée ici fonctionne mais on peut très bien faire autrement !
On trouvera ici la description exhaustive d’un schéma YACS.
Note
Le module HOMARD propose une création automatique de schéma YASC à partir d’un cas précédemment créé. Pour la mettre en oeuvre, consulter Le schéma YACS
Présentation générale¶
On va décrire ici un schéma s’appliquant à un calcul pour lequel on cherche à stabiliser une valeur. Le calcul démarre sur un maillage initial puis HOMARD enchaîne avec une adaptation. On refait un calcul sur ce nouveau maillage et son résultat est analysé. En fonction de cette analyse, le couplage continue ou non. L’allure générale du schéma est la suivante :

Note
Parmi l’ensemble des données manipulées, certaines sont immuables : le nom du répertoire de calcul, le nom du cas, le nom de l’hypothèse d’adaptation, etc. Il a été choisi de les imposer “en dur” dans les différents paramètres de service ou au sein des scripts python. On pourrait également les définir a priori dans un noeud PresetNode et ensuite les transmettre par des liens. Nous n’avons pas retenu cette solution car elle augmente fortement le nombre de paramètres et de liens attachés à chaque noeud. Cela est très pénalisant pour la lisibilité du schéma. Les seules données qui vont circuler sont celles imposées par la description du service et celles qui évoluent au cours de l’exécution du schéma.
Les boîtes¶
Les boîtes principales sont :
DataInit : initialisation du maillage initial
Etude_Initialisation : lancement du module HOMARD dans SALOME
Boucle_de_convergence : gestion de la boucle d’alternance calcul/adaptation
Bilan : affichage final
DataInit¶
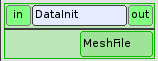
Cette boîte est un noeud élémentaire de type PresetNode. Sa seule fonction est d’initialiser la variable MeshFile qui contient le nom du fichier du maillage initial.
<datanode name="DataInit">
<parameter name="MeshFile" type="string">
<value><string>/home/D68518/HOMARD_SVN/trunk/training/tet_aster_ther/maill.00.med</string></value>
</parameter>
</datanode>
Etude_Initialisation¶
La boîte Etude_Initialisation lance le composant HOMARD dans SALOME. C’est un bloc composé de deux parties, qui sont invariables quelle que soit l’application envisagée :
StudyCreation : noeud python
UpdateStudy : service du composant HOMARD

Le noeud python StudyCreation sert à initialiser l’étude SALOME qui est fournie en sortie :
<inline name="StudyCreation">
<script><code><![CDATA[
import orbmodule
import SALOMEDS_idl
import HOMARD
import HOMARD_Gen_idl
import HOMARD_Cas_idl
import HOMARD_Iteration_idl
import HOMARD_Hypothesis_idl
import HOMARD_Zone_idl
import HOMARD_Boundary_idl
clt = orbmodule.client()
CurrentStudy = clt.Resolve("/Study")
]]></code></script>
</inline>
Le service UpdateStudy affecte cette étude à une instance de HOMARD.
<service name="UpdateStudy">
<component>HOMARD</component>
<load container="DefaultContainer"/>
<method>UpdateStudy</method>
</service>
Boucle_de_convergence¶
La boîte Boucle_de_convergence est une boucle de type WhileLoop. La condition est initialisée à 1 : le bloc interne Alternance_Calcul_HOMARD est exécuté. Au sein de ce bloc, on calcule et on adapte le maillage ; quand le processus doit s’arrêter soit par suite d’erreur, soit par convergence, la condition passe à 0. La boucle s’achève et on passe à la boîte suivante, Bilan.

Bilan¶

Cette boîte est un noeud python qui prend en entrée une chaîne de caractères, MessInfo. Si tout s’est bien passé, ce message est vide. Une fenêtre QT apparaît pour confirmer la convergence. S’il y a eu un problème, le message contient les messages émis au cours des calculs. La fenêtre QT affiche ce message.
<inline name="Bilan">
<script><code><![CDATA[
from PyQt5 import QtWidgets
import sys
app = QtWidgets.QApplication(sys.argv)
MessageBoxTitle = "Bilan"
if MessInfo == "" :
MessInfo = "Le calcul est converge."
QtWidgets.QMessageBox.information(None, MessageBoxTitle, MessInfo)
else :
QtWidgets.QMessageBox.critical(None, MessageBoxTitle, MessInfo)
]]></code></script>
<inport name="MessInfo" type="string"/>
</inline>
La boucle de calculs¶
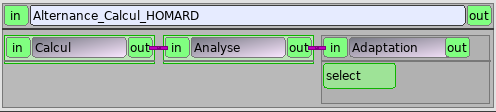
Cette boîte est un bloc qui gère le calcul, l’analyse et l’adaptation.
Calcul¶
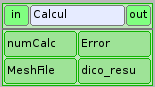
Cette boîte est un noeud python qui va piloter le calcul. En entrée, on trouve le numéro du calcul (0 au départ) et le nom du fichier qui contient le maillage sur lequel calculer. En sortie, on trouve un entier qui représente l’erreur sur ce calcul (0 si tout va bien) et un dictionnaire python rassemblant les résultats du calcul. Le corps du noeud est constitué par le lancement d’un script python qui active le calcul.
<script><code><![CDATA[
import sys
import os
#
rep_calc = "/home/D68518/HOMARD_SVN/trunk/training/tet_aster_ther"
rep_script = os.path.dirname("/home/D68518/HOMARD_SVN/trunk/training/script")
sys.path.append(rep_script)
from ScriptAster import Script
#
argu = ["-v"]
argu.append("--rep_calc=" + rep_calc)
argu.append("--num=%d" % numCalc)
argu.append("--mesh_file=" + MeshFile)
#
Script_A = Script(argu)
#
Error, message_erreur, dict_resu = Script_A.compute ()
#
dict_resu["rep_calc"] = rep_calc
#
]]></code></script>
Dans cet exemple, il faut définir :
rep_calc : le répertoire dans lequel sera exécuté le calcul.
rep_script : le répertoire dans lequel se trouve le python qui lancera le calcul. Ce répertoire est à ajouter au PATH. Depuis ce répertoire, on importera “Script” depuis le fichier ScriptAster.py
Le python Script est programmé comme l’utilisateur le souhaite pour que le calcul puisse être effectué sur le maillage courant. Selon le mode de lancement du code de calcul, on peut avoir besoin d’autres informations, comme le numéro du calcul ou le répertoire du calcul par exemple. La liberté est totale. Dans notre cas, les arguments d’entrée sont le nom du fichier de maillage, le numéro du calcul et le répertoire de calcul sous la forme de la liste python [« –rep_calc=rep_calc », « –num=numCalc », « –mesh_file=MeshFile »] ].
En revanche la sortie du script doit obéir à la règle suivante. On récupère un code d’erreur, un message d’erreur et un dictionnaire. Ce dictionnaire contient obligatoirement les clés suivantes :
« FileName » : le nom du fichier qui contient les résultats du calcul
« V_TEST » : la valeur dont on veut tester la convergence
Adaptation¶

La boîte Adaptation est un noeud Switch piloté par le code d’erreur du calcul précédent. Si ce code est nul, YACS activera la boîte Adaptation_HOMARD qui lancera l’adaptation. Si le code n’est pas nul, on passe directement dans la boîte Arret_boucle.
Adaptation_HOMARD¶
La première tâche à exécuter concerne l’initialisation des données nécessaires à HOMARD dans la boîte HOMARD_Initialisation. Cette boîte est un noeud switch piloté par le numéro du calcul. Au démarrage, le numéro est nul et YACS active la boîte Iter_1.
Iter_1¶

Cette boîte commence par créer le cas HOMARD en appelant le service CreateCase.
<service name="CreateCase">
<node>Etude_Initialisation.UpdateStudy</node>
<method>CreateCase</method>
<inport name="CaseName" type="string"/>
<inport name="MeshName" type="string"/>
<inport name="FileName" type="string"/>
<outport name="return" type="HOMARD_Cas"/>
</service>
Le nom du cas CaseName est imposé à « Calcul ». Le paramètre d’entrée MeshName est imposé à « BOX ». Le paramètre d’entrée FileName est issu de la sortie du calcul précédent. Le paramètre de sortie est une instance de cas.
<parameter>
<tonode>Boucle_de_convergence.Alternance_Calcul_HOMARD.Adaptation.p0_Adaptation_HOMARD.HOMARD_Initialisation.p1_Iter_1.CreateCase</tonode><toport>CaseName</toport>
<value><string>Calcul</string></value>
</parameter>
<parameter>
<tonode>Boucle_de_convergence.Alternance_Calcul_HOMARD.Adaptation.p0_Adaptation_HOMARD.HOMARD_Initialisation.p1_Iter_1.CreateCase</tonode><toport>MeshName</toport>
<value><string>BOX</string></value>
</parameter>
Les options de ce cas doivent maintenant être renseignées. C’est fait par le noeud python CaseOptions. Il est impératif de renseigner le répertoire de calcul. On regardera la description des fonctions dans Le cas. En sortie, on récupère l’instance de l’itération correspondant à l’état initial du cas.
<inline name="Case_Options">
<script><code><![CDATA[
import os
# Repertoire d'adaptation
DirName = "/home/D68518/HOMARD_SVN/trunk/training/tet_aster_ther/HOMARD"
Case.SetDirName(DirName)
Case.SetConfType(1)
# Iteration 0 associee
Iter0 = Case.GetIter0()
]]></code></script>
<inport name="Case" type="HOMARD_Cas"/>
<outport name="Iter0" type="HOMARD_Iteration"/>
</inline>
Enfin, une hypothèse est créée en appelant le service CreateHypothese. Le paramètre de sortie est une instance d’hypothèse.
Homard_Exec¶
Une fois initialisée, l’adaptation peut être calculée. C’est le but de la boîte Homard_Exec, sous forme d’un script python.

Le répertoire de calcul est récupéré. Le nom du maillage est rappelé.
<inline name="HOMARD_Exec">
<script><code><![CDATA[
import os
# Repertoire d'execution
DirName = "/home/D68518/HOMARD_SVN/trunk/training/tet_aster_ther"
MeshName = "BOX"
../..
]]></code></script>
<inport name="NumAdapt" type="int"/>
<inport name="LastIter" type="HOMARD_Iteration"/>
<inport name="Hypo" type="HOMARD_Hypothesis"/>
<inport name="dict_resu" type="pyobj"/>
<outport name="OK" type="bool"/>
<outport name="MessInfo" type="string"/>
<outport name="MeshFile" type="string"/>
</inline>
L’hypothèse transmise en paramètre d’entrée est caractérisée (voir L’hypothèse) :
# . Nom de l'hypothese
# --------------------
HypoName = Hypo.GetName()
#
# . Options
# ---------
# . Le mode d'adaptation : raffinement et deraffinement selon un champ
Hypo.SetAdapRefinUnRef(1, 1, 1)
# . Nom du champ
Hypo.SetField("ERREUR")
# . Valeurs prises par maille
Hypo.SetUseField(0)
# . Composante
Hypo.AddComp("ERTABS")
# . Mode de pilotage
Hypo.SetRefinThr(4, 3)
Hypo.SetUnRefThr(4, 4)
#
# . Interpolation
Hypo.SetTypeFieldInterp(2)
Hypo.AddFieldInterp("TEMPERATURE")
#
# . Taille de maille limite
aux = 0.0015
Hypo.SetDiamMin(aux)
Il faut établir un nom pour la future itération. Pour s’assurer que le nom n’a jamais été utilisé, on met en place un mécanisme de nommage incrémental à partir du nom de l’itération initiale. Comme ce nom initial est le nom du maillage initial, on obtient une succession de noms sous la forme : M_001, M_002, M_003, etc.
# Nom de la future iteration
# ==========================
# . Nom de l'iteration precedente
LastIterName = LastIter.GetName()
aux = '%03d' % NumAdapt
# . A l'iteration 1, on complete
if NumAdapt == 1 :
IterName = LastIterName + "_" + aux
# . Ensuite, on substitue
else :
IterName = LastIterName[:-3] + aux
L’itération est complétée : hypothèse, futur maillage, champ (voir L’itération) :
# Creation de l'iteration
# =======================
Iter = LastIter.NextIteration(IterName)
#
# Options de l'iteration
# ======================
# . Association de l'hypothese
Iter.AssociateHypo(HypoName)
#
# . Le nom du futur maillage
Iter.SetMeshName(MeshName)
#
# . Le fichier du futur maillage
aux = '%02d' % NumAdapt
MeshFile = os.path.join (DirName, "maill."+aux+".med")
Iter.SetMeshFile(MeshFile)
#
# . Le fichier contenant les champs
FileName = dict_resu["FileName"]
Iter.SetFieldFile(FileName)
L’itération est calculée. Si tout s’est bien passé, la variable OK vaut 1 : on pourra continuer l’exécution du schéma. S’il y a eu un problème, la variable OK vaut 0 pour signifier que le calcul doit s’arrêter ; on donne alors un message d’erreur.
# Calcul
# ======
Error = Iter.Compute(1,1)
#
# Arret de la boucle si erreur
# ============================
if Error :
OK = 0
MessInfo = "Erreur dans HOMARD pour l'adaptation numero %d" % NumAdapt
else :
OK = 1
MessInfo = " "
Après cette exécution, le processus sort du noeud Adaptation_HOMARD, puis du noeud Adaptation. On arrive alors au noeud d’analyse.
Iter_n¶
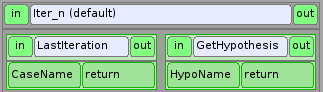
Aux passages suivants dans le bloc d’adaptation, il faut récupérer :
la dernière itération créée pour la poursuivre : service LastIteration (voir L’itération)
l’hypothèse créée : service GetHypothesis (voir L’hypothèse)
On passe ensuite dans le noeud Homard_Exec pour calculer le nouveau maillage.
Arret_boucle¶

Le bloc Arret_boucle n’est présent que pour faire transiter des variables car les paramètres d’entrée des noeuds doivent toujours être remplis. C’est un python très simple :
<bloc name="Arret_boucle">
<inline name="Arret">
<script><code><![CDATA[
OK = 0
MeshFile = " "
]]></code></script>
<inport name="MessInfo" type="string"/>
<outport name="OK" type="bool"/>
<outport name="MeshFile" type="string"/>
<outport name="MessInfo" type="string"/>
</inline>
</bloc>
Analyse¶
Le bloc Analyse est un script python qui assure le contrôle complet du processus en examinant successivement les causes d’erreur possible.
<inline name="Analyse">
<script><code><![CDATA[
global NumCalc
global resu1
# Valeurs par defaut
NumCalcP1 = NumCalc + 1
FileName = " "
#
NbCalcMax = 5
#
MessInfo = None
Error = 0
while not Error :
../..
]]></code></script>
<inport name="NumCalc" type="int"/>
<inport name="ErrCalc" type="int"/>
<inport name="dict_resu" type="pyobj"/>
<outport name="Error" type="int"/>
<outport name="NumCalcP1" type="int"/>
<outport name="FileName" type="string"/>
<outport name="MessInfo" type="string"/>
</inline>
On commence par analyser le retour du code de calcul :
# Si le calcul a fini en erreur, on arrete :
#
if ErrCalc :
MessInfo = "Erreur de calcul numero %d" % ErrCalc
Error = abs(ErrCalc)
break
Vérification de la présence du nom du fichier de résultats dans le dictionnaire des résultats :
# Si le fichier n'a pas ete defini, on arrete :
#
if ( "FileName" in dict_resu ) :
FileName = dict_resu["FileName"]
else :
MessInfo = "Le fichier du maillage n'a pas ete defini"
Error = -2
break
Vérification de la convergence. Cela suppose que la valeur à tester est présente dans le dictionnaire sous la clé “V_TEST”. Ici, on a mis en place un test sur la variation de la valeur d’un calcul à l’autre. Au premier passage, on ne teste rien. Aux passages suivants, on teste si la variation relative est inférieure à 1 millième. On aurait pu mettre en place un test absolu si on avait récupéré un niveau global d’erreur par exemple.
# Si le critere est respecte, on arrete :
#
if ( "V_TEST" in dict_resu ) :
valeur_v = dict_resu["V_TEST"]
if NumCalc == 0 :
resu1 = [valeur_v]
else :
resu1.append(valeur_v)
if NumCalc > 2 :
solu_m1 = resu1[-2]
rap = ( resu1[-1] - solu_m1 ) / solu_m1
if abs(rap) < 0.001 :
MessInfo = ""
Error = -9999
break
else :
MessInfo = "La valeur a tester n'a pas ete fournie"
Error = -3
break
#
# Si on depasse le maximum, on arrete :
Enfin, on vérifie que l’on ne dépasse pas un nombre maximal d’adaptations :
# Si on depasse le maximum, on arrete :
#
if NumCalc > NbCalcMax :
MessInfo = "La limite en nombre de calculs a ete atteinte : %d" % NbCalcMax
Error = -1
break
Utiliser ce schéma¶
- Pour reproduire cet exemple, on pourra télécharger :
Il faut l’adapter à la simulation envisagée. En particulier, il faut :
ajuster les noms des fichiers et des répertoires
fournir un script de lancement du calcul respectant les consignes évoquées ci-avant
choisir les hypothèses de pilotage de l’adaptation
mettre en place le test d’arrêt