12.4. Requirements for describing a state sampling¶
In general, it is useful to have a sampling of states when you are interested in analyses that benefit from knowledge of a set of simulations or a set of similar measurements, but each obtained for a different state.
This is the case for the explicit definition of simulatable states of Checking algorithm “SamplingTest”, Task algorithm “EnsembleOfSimulationGenerationTask” and Task algorithm “MeasurementsOptimalPositioningTask”.
All these states can be described explicitly or implicitly, to simplify their listing. Various possible descriptions are given below, followed by very simple examples to show the types of state distribution obtained in the space.
12.4.1. Explicit or implicit description of the state sampling collection¶
The state sampling collection can be described using dedicated keywords in the command set of an algorithm that requires it.
The sampling of the states  can be provided explicitly or in
the form of hypercubes, explicit or sampled according to common distributions,
or using Latin Hypercube Sampling (LHS) or Sobol sequences. Depending on the
method, the sample will be included in the domain described by its bounds, or
will come from the description of the unbounded domain of state variables.
can be provided explicitly or in
the form of hypercubes, explicit or sampled according to common distributions,
or using Latin Hypercube Sampling (LHS) or Sobol sequences. Depending on the
method, the sample will be included in the domain described by its bounds, or
will come from the description of the unbounded domain of state variables.
These possible keywords are:
- SampleAsExplicitHyperCube
List of list of real values. This key describes the calculations points as an hyper-cube, from a given list of explicit sampling of each variable as a list. That is then a list of lists, each of them being potentially of different size. By nature, the points are included in the domain defined by the bounds of the explicit lists for each variable.
Example :
{"SampleAsExplicitHyperCube":[[0.,0.25,0.5,0.75,1.], [-2,2,1]]}for a state space of dimension 2.
- SampleAsIndependentRandomVariables
List of triplets [Name, Parameters, Number]. This key describes the calculations points as an hyper-cube, for which the points on each axis come from a independent random sampling of the axis variable, under the specification of the distribution, its parameters and the number of points in the sample, as a list [Name, Parameters, Number] for each axis. Unlike sampling described by the keyword “SampleAsIndependentRandomVectors”, points are explicitly distributed over a regular hypercube. The possible distribution names are ‘normal’ of parameters (mean,std), ‘lognormal’ of parameters (mean,sigma), ‘uniform’ of parameters (low,high), or ‘weibull’ of parameter (shape). That is then a list of the same size than the one of the state. By nature, the points are included in the unbounded or bounded domain, depending on the characteristics of the distributions chosen for each variable.
Example :
{"SampleAsIndependentRandomVariables":[['normal',[0.,1.],3], ['uniform',[-2,2],4]]}for a state space of dimension 2.
- SampleAsIndependentRandomVectors
List of pairs [Name, Parameters], plus [Dimension, Number]. This key describes the calculation points in the form of particular distributions defined for each dimension, resulting in random vectors whose individual components follow the required distribution. Unlike the sampling described by the keyword “SampleAsIndependentRandomVariables”, the points are not distributed over a regular hypercube. The distribution on each axis variable is specified by its name and parameters, in the form of a list [Name, Parameters] for each axis. This list of pairs, whose number is identical to the size of the state space, is completed by a pair of integers [Dimension, Number] containing the dimension of the state space and the desired number of sampling points. Possible distribution names are ‘normal’ with parameters (mean,std), ‘lognormal’ with parameters (mean,sigma), ‘uniform’ with parameters (low,high), ‘loguniform’ with parameters (low,high), or ‘weibull’ with parameters (shape). By their very nature, points are included in the unbounded or bounded domain, depending on the characteristics of the distributions chosen for each variable. Distributions can be different for each axis.
Example :
{"SampleAsIndependentRandomVectors":[['normal',[0.,1.]], ['uniform',[-2,2]]]}for a state space of dimension 2.
- SampleAsMinMaxLatinHyperCube
List of real valued pairs [Min, Max], plus [Dimension, Number]. This key describes the bounded domain in which the calculations points will be placed, from a [Min, Max] pair for each state component. The lower bounds are included. This list of pairs, identical in number to the size of the state space, is augmented by a pair of integers [Dimension, Number] containing the dimension of the state space and the desired number of sample points. Sampling is then automatically constructed using the Latin hypercube method (LHS). By nature, the points are included in the domain defined by the explicit bounds.
Example :
{"SampleAsMinMaxLatinHyperCube":[[0.,1.],[-1,3]]+[[2,11]]}for a state space of dimension 2 and for 11 sampling points.
- SampleAsMinMaxSobolSequence
List of real valued pairs [Min, Max], plus [Dimension, Number]. This key describes the bounded domain in which the calculations points will be placed, from a [Min, Max] pair for each state component. The lower bounds are included. This list of pairs, identical in number to the size of the state space, is augmented by a pair of integers [Dimension, Number] containing the dimension of the state space and the minimum desired number of sample points (by construction, the number of points generated in the Sobol sequence will be the power of 2 immediately above this minimum number). Sampling is then automatically constructed using the Sobol sequence method. By nature, the points are included in the domain defined by the explicit bounds.
Remark: it is required to have Scipy version 1.7.0 or higher to use this sampling option.
Example :
{"SampleAsMinMaxSobolSequence":[[0.,1.],[-1,3]]+[[2,11]]}for a state space of dimension 2 and 11 sampling points (there will be 16 points in practice).
- SampleAsMinMaxStepHyperCube
List of triplets of real values [Min, Max, Step]. This key describes the calculations points as an hyper-cube, from a given list of implicit sampling of each variable by a triplet [Min, Max, Step]. That is then a list of the same size than the one of the state. The bounds are included. By nature, the points are included in the domain defined by the explicit bounds.
Example :
{"SampleAsMinMaxStepHyperCube":[[0.,1.,0.25],[-1,3,1]]}for a state space of dimension 2.
- SampleAsnUplet
List of states. This key describes the calculations points as a list of n-uplets, each n-uplet being a state. By nature, points are included in the bounded domain defined as the convex envelope of explicitly designated points.
Example :
{"SampleAsnUplet":[[0,1,2,3],[4,3,2,1],[-2,3,-4,5]]}for 3 points in a state space of dimension 4.
Beware of the size of the implicit hypercube (and then to the number of computations) that can be reached, it can grow quickly to be quite large.
12.4.2. Simple examples of state-space distributions¶
To illustrate the commands, we propose here simple state distributions obtained in a 2-dimensional state space (to be representable), and the commands that enable them to be obtained. We arbitrarily choose to place 25 states in each case. In most of the commands, since the states are described separately according to each coordinate, 5 coordinate values are requested per axis.
The first three keywords illustrate the same distribution, as they are simply different ways of describing it.
12.4.2.1. Explicit state distribution by keyword “SampleAsnUplet”¶
Explicit sample generation command by “SampleAsnUplet” is as follows:
[...]
"SampleAsnUplet":[[0, 0], [0, 1], [0, 2], [0, 3], [0, 4],
[1, 0], [1, 1], [1, 2], [1, 3], [1, 4],
[2, 0], [2, 1], [2, 2], [2, 3], [2, 4],
[3, 0], [3, 1], [3, 2], [3, 3], [3, 4],
[4, 0], [4, 1], [4, 2], [4, 3], [4, 4]]
[...]
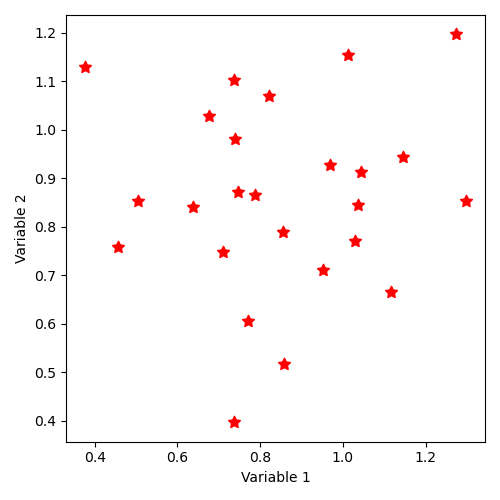
La répartition des états ainsi décrite correspond à l’illustration :
Note: here we’ve chosen an ordered distribution, similar to those we’ll obtain much more synthetically with some of the following commands, precisely to illustrate this point.
12.4.2.2. Implicit state distribution by keyword “SampleAsExplicitHyperCube”¶
Implicit sample generation command by “SampleAsExplicitHyperCube” is as follows:
[...]
"SampleAsExplicitHyperCube":[[0, 1, 2, 3, 4], [0, 1, 2, 3, 4]]
# ou
"SampleAsExplicitHyperCube":[range(0, 5), range(0, 5)]
[...]
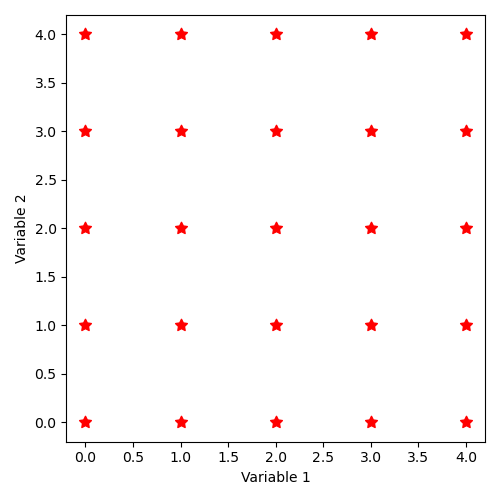
The distribution of states thus described corresponds to the illustration:
12.4.2.3. Implicit state distribution by keyword “SampleAsMinMaxStepHyperCube”¶
Implicit sample generation command by “SampleAsMinMaxStepHyperCube” is as follows:
[...]
"SampleAsMinMaxStepHyperCube":[[0, 4, 1], [0, 4, 1]]
[...]
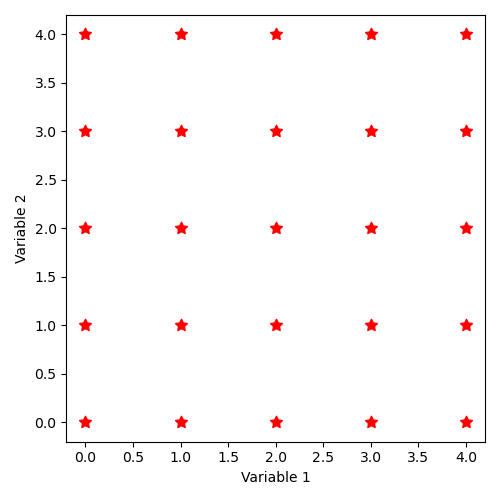
The distribution of states thus described corresponds to the illustration:
12.4.2.4. Implicit state distribution by keyword “SampleAsMinMaxLatinHyperCube”¶
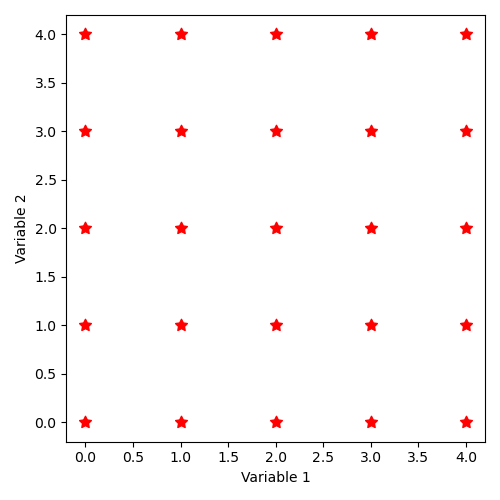
Implicit sample generation command by “SampleAsMinMaxLatinHyperCube”, in dimension 2 et and with 25 points, is as follows:
[...]
"SampleAsMinMaxLatinHyperCube":[[0, 4], [0, 4], [2, 25]]
[...]
The distribution of states thus described corresponds to the illustration:
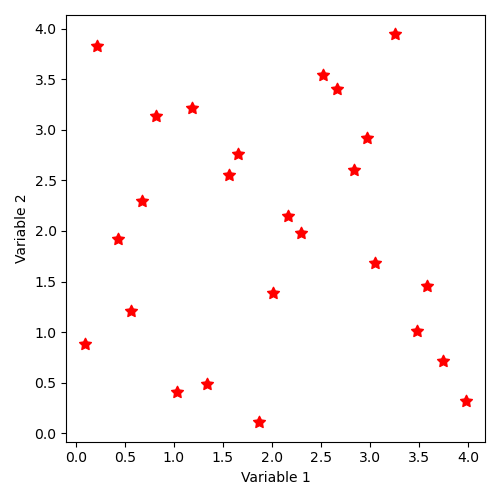
12.4.2.5. Implicit state distribution by keyword “SampleAsMinMaxSobolSequence”¶
Implicit sample generation command by “SampleAsMinMaxSobolSequence”, in dimension 2 et and with 25 points, is as follows:
[...]
"SampleAsMinMaxSobolSequence":[[0, 4], [0, 4], [2, 25]]
[...]
The distribution of states (there will be 32 here by construction principle of the Sobol sequence) thus described corresponds to the illustration:
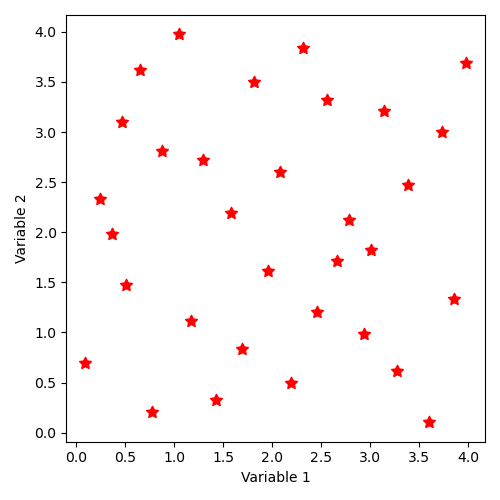
12.4.2.6. Implicit state distribution by keyword “SampleAsIndependentRandomVariables” with normal laws¶
Implicit sample generation command by “SampleAsIndependentRandomVariables” is as follows, using a normal distribution (1,1) by coordinate:
[...]
"SampleAsIndependentRandomVariables":[['normal', [1, 1], 5], ['normal', [1, 1], 5]]
[...]
The distribution of states thus described corresponds to the illustration:
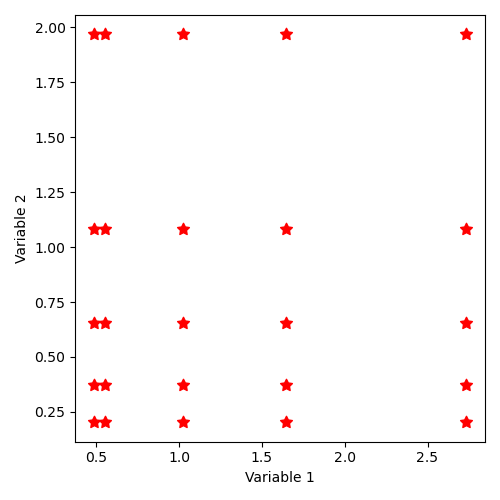
12.4.2.7. Implicit state distribution by keyword “SampleAsIndependentRandomVariables” with log-normal laws¶
Implicit sample generation command by “SampleAsIndependentRandomVariables” is as follows, using a log-normal distribution (1,1) (i.e. whose logarithmic distribution is normal) by coordinate:
[...]
"SampleAsIndependentRandomVariables":[['lognormal', [1, 1], 5], ['lognormal', [1, 1], 5]]
[...]
The distribution of states thus described corresponds to the illustration:
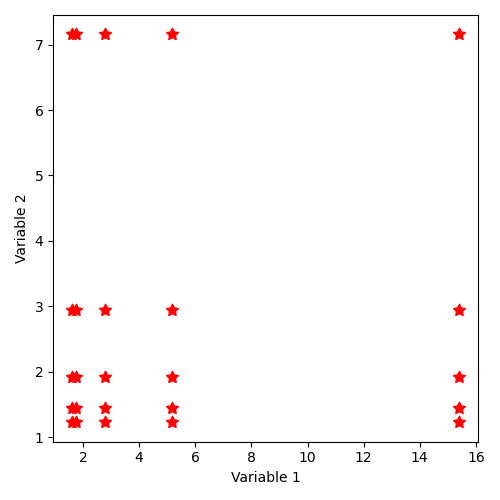
12.4.2.8. Implicit state distribution by keyword “SampleAsIndependentRandomVariables” with uniform laws¶
Implicit sample generation command by “SampleAsIndependentRandomVariables” is as follows, using a uniform distribution between 0.01 and 1 for coordinate distribution:
[...]
"SampleAsIndependentRandomVariables":[['uniform', [0.01, 1], 5], ['uniform', [0.01, 1], 5]]
[...]
The distribution of states thus described corresponds to the illustration:
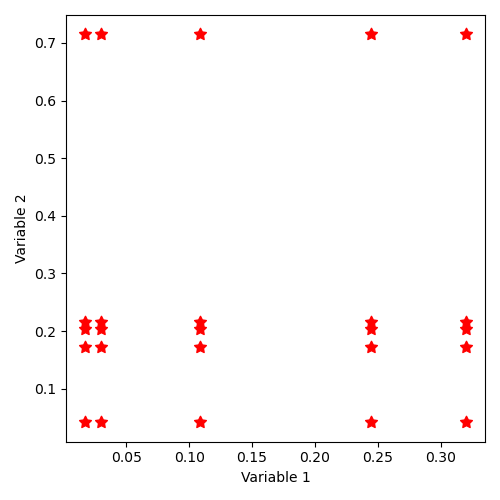
12.4.2.9. Implicit state distribution by keyword “SampleAsIndependentRandomVariables” with log-uniform laws¶
Implicit sample generation command by “SampleAsIndependentRandomVariables” is as follows, using a uniform distribution between 0.01 and 1 (i.e. whose logarithmic distribution is uniform) for coordinate distribution:
[...]
"SampleAsIndependentRandomVariables":[['loguniform', [0.01, 1], 5], ['loguniform', [0.01, 1], 5]]
[...]
The distribution of states thus described corresponds to the illustration:
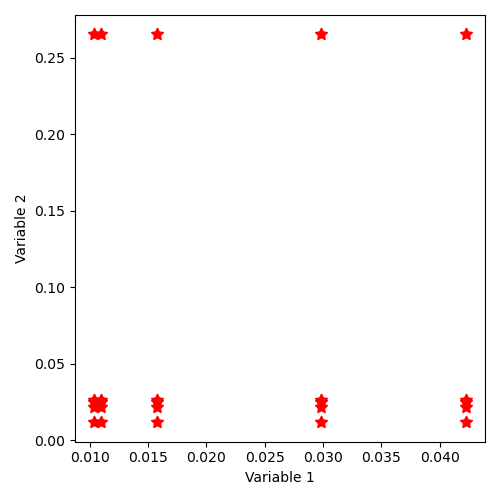
12.4.2.10. Implicit state distribution by keyword “SampleAsIndependentRandomVariables” with Weibull laws¶
Implicit sample generation command by “SampleAsIndependentRandomVariables” is as follows, using a 1-parameter Weibull distribution of value 5 for coordinate distribution:
[...]
"SampleAsIndependentRandomVariables":[['weibull', [5], 5], ['weibull', [5], 5]]
[...]
The distribution of states thus described corresponds to the illustration:
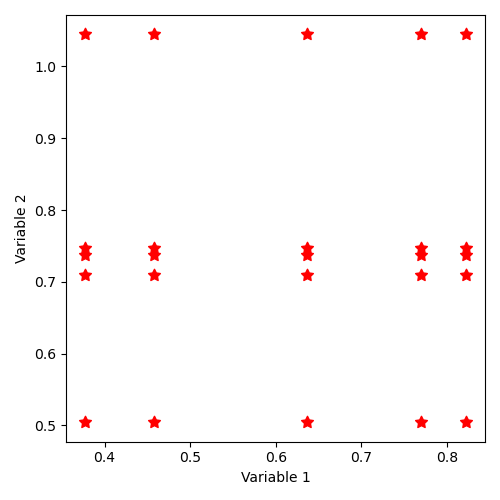
12.4.2.11. Implicit state distribution by keyword “SampleAsIndependentRandomVectors” with normal laws¶
The implicit command for generating samples of independent vectors by “SampleAsIndependentRandomVectors” is as follows, in dimension 2 and with 25 points, using a normal distribution (1,1) for each coordinate:
[...]
"SampleAsIndependentRandomVectors":[['normal', [1, 1]], ['normal', [1, 1]], [2, 25]]
[...]
The distribution of states thus described corresponds to the illustration:
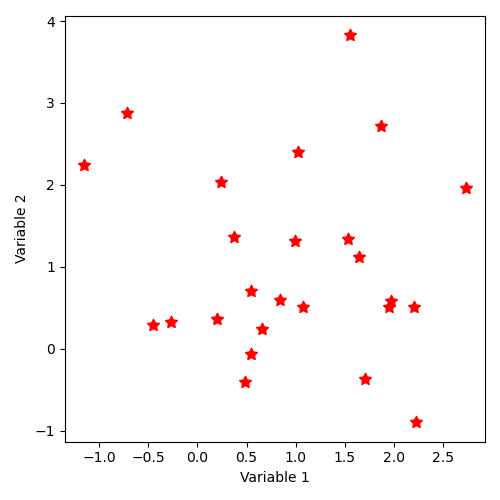
12.4.2.12. Implicit state distribution by keyword “SampleAsIndependentRandomVectors” with log-normal laws¶
The implicit command for generating samples of independent vectors by “SampleAsIndependentRandomVectors” is as follows, in dimension 2 and with 25 points, using a log-normal distribution (1,1) (i.e. whose logarithmic distribution is normal) for each coordinate:
[...]
"SampleAsIndependentRandomVectors":[['lognormal', [1, 1]], ['lognormal', [1, 1]], [2, 25]]
[...]
The distribution of states thus described corresponds to the illustration:
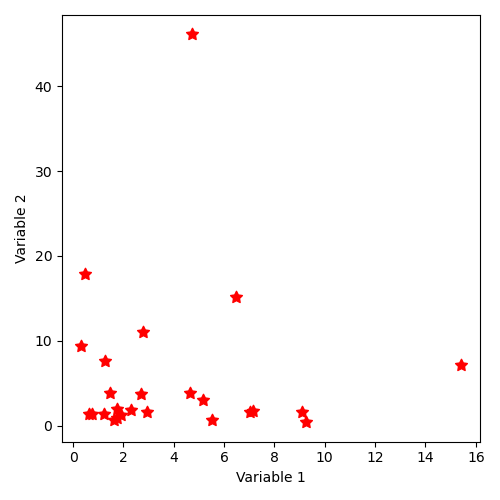
12.4.2.13. Implicit state distribution by keyword “SampleAsIndependentRandomVectors” with uniform laws¶
The implicit command for generating samples of independent vectors by “SampleAsIndependentRandomVectors” is as follows, in dimension 2 and with 25 points, using a uniform distribution between 0.01 and 1 for each coordinate:
[...]
"SampleAsIndependentRandomVectors":[['normal', [0.01, 1]], ['normal', [0.01, 1]], [2, 25]]
[...]
The distribution of states thus described corresponds to the illustration:
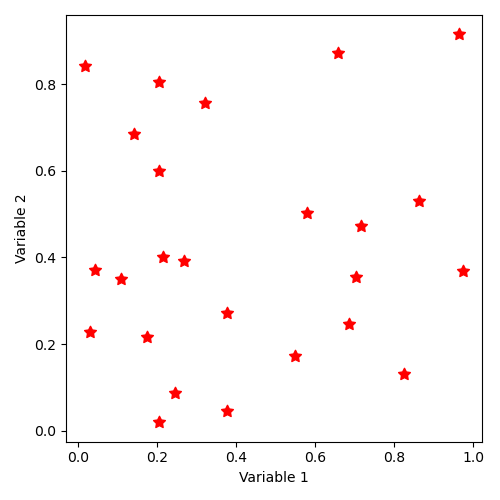
12.4.2.14. Implicit state distribution by keyword “SampleAsIndependentRandomVectors” with log-uniform laws¶
The implicit command for generating samples of independent vectors by “SampleAsIndependentRandomVectors” is as follows, in dimension 2 and with 25 points, using a log-uniform distribution (i.e. whose logarithmic distribution is uniform) between 0.01 and 1 for each coordinate:
[...]
"SampleAsIndependentRandomVectors":[['lognormal', [1, 1]], ['lognormal', [1, 1]], [2, 25]]
[...]
The distribution of states thus described corresponds to the illustration:
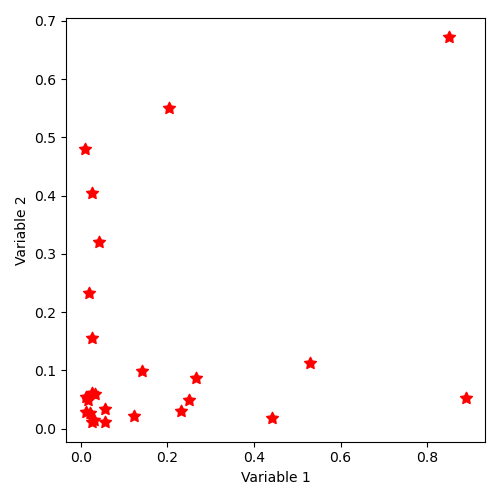
12.4.2.15. Implicit state distribution by keyword “SampleAsIndependentRandomVectors” with Weibull laws¶
The implicit command for generating samples of independent vectors by “SampleAsIndependentRandomVectors” is as follows, in dimension 2 and with 25 points, using a 1-parameter Weibull distribution of value 5 for coordinate distribution:
[...]
"SampleAsIndependentRandomVectors":[['weibull', [5]], ['weibull', [5]], [2, 25]]
[...]
The distribution of states thus described corresponds to the illustration: