13.4. Calculation algorithm “DerivativeFreeOptimization”¶
13.4.1. Description¶
This algorithm realizes an estimation of the state of a system by minimization
without gradient of a cost function  , using a search method by simplex
type or similar approximation. It is a method that does not use the derivatives
of the cost function.
, using a search method by simplex
type or similar approximation. It is a method that does not use the derivatives
of the cost function.
It falls in the same category than the Calculation algorithm “DifferentialEvolution”, Calculation algorithm “ParticleSwarmOptimization”, Calculation algorithm “SimulatedAnnealing”, Calculation algorithm “TabuSearch”.
This is a mono-objective optimization method allowing for global minimum search
of a general error function of type  ,
,  or
or
 , with or without weights. The default error function is the
augmented weighted least squares function, classically used in data
assimilation.
, with or without weights. The default error function is the
augmented weighted least squares function, classically used in data
assimilation.
13.4.2. Some noteworthy properties of the implemented methods¶
To complete the description, we summarize here a few notable properties of the algorithm methods or of their implementations. These properties may have an influence on how it is used or on its computational performance. For further information, please refer to the more comprehensive references given at the end of this algorithm description.
The optimization methods proposed by this algorithm perform a non-local search for the minimum, without however ensuring a global search. This is the case when optimization methods have the ability to avoid being trapped by the first local minimum found. These capabilities are sometimes heuristic.
The methods proposed by this algorithm do not require derivation of the objective function or of one of the operators, thus avoiding this additional calculation time when derivatives are calculated numerically by multiple evaluations.
The methods proposed by this algorithm have no internal parallelism or numerical derivation of operator(s), and therefore cannot take advantage of computer resources for distributing calculations. The methods are sequential, and any use of parallelism resources is therefore reserved for observation or evolution operators, i.e. user codes.
The methods proposed by this algorithm achieve their convergence on one or more residue or number criteria. In practice, there may be several convergence criteria active simultaneously.
The residue can be a conventional measure based on a gap (e.g. “calculation-measurement gap”), or be a significant value for the algorithm (e.g. “nullity of gradient”).
The number is frequently a significant value for the algorithm, such as a number of iterations or a number of evaluations, but it can also be, for example, a number of generations for an evolutionary algorithm.
Convergence thresholds need to be carefully adjusted, to reduce the gobal calculation cost, or to ensure that convergence is adapted to the physical case encountered.
13.4.3. Optional and required commands¶
The general required commands, available in the editing user graphical or textual interface, are the following:
- Background
Vector. The variable indicates the background or initial vector used, previously noted as
 . Its value is defined as a
“Vector” or “VectorSerie” type object. Its availability in output is
conditioned by the boolean “Stored” associated with input.
. Its value is defined as a
“Vector” or “VectorSerie” type object. Its availability in output is
conditioned by the boolean “Stored” associated with input.
- BackgroundError
Matrix. This indicates the background error covariance matrix, previously noted as
 . Its value is defined as a “Matrix” type
object, a “ScalarSparseMatrix” type object, or a “DiagonalSparseMatrix”
type object, as described in detail in the section
Requirements to describe covariance matrices. Its availability in output is
conditioned by the boolean “Stored” associated with input.
. Its value is defined as a “Matrix” type
object, a “ScalarSparseMatrix” type object, or a “DiagonalSparseMatrix”
type object, as described in detail in the section
Requirements to describe covariance matrices. Its availability in output is
conditioned by the boolean “Stored” associated with input.
- EvolutionError
Matrix. The variable indicates the evolution error covariance matrix, usually noted as
 . It is defined as a “Matrix” type
object, a “ScalarSparseMatrix” type object, or a “DiagonalSparseMatrix”
type object, as described in detail in the section
Requirements to describe covariance matrices. Its availability in output is
conditioned by the boolean “Stored” associated with input.
. It is defined as a “Matrix” type
object, a “ScalarSparseMatrix” type object, or a “DiagonalSparseMatrix”
type object, as described in detail in the section
Requirements to describe covariance matrices. Its availability in output is
conditioned by the boolean “Stored” associated with input.
- EvolutionModel
Operator. The variable indicates the evolution model operator, usually noted
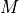 , which describes an elementary step of evolution. Its value
is defined as a “Function” type object or a “Matrix” type one. In the
case of “Function” type, different functional forms can be used, as
described in the section Requirements for functions describing an operator. If there
is some control
, which describes an elementary step of evolution. Its value
is defined as a “Function” type object or a “Matrix” type one. In the
case of “Function” type, different functional forms can be used, as
described in the section Requirements for functions describing an operator. If there
is some control  included in the evolution model, the operator has
to be applied to a pair
included in the evolution model, the operator has
to be applied to a pair  .
.
- Observation
List of vectors. The variable indicates the observation vector used for data assimilation or optimization, and usually noted
 .
Its value is defined as an object of type “Vector” if it is a single
observation (temporal or not) or “VectorSeries” if it is a succession of
observations. Its availability in output is conditioned by the boolean
“Stored” associated in input.
.
Its value is defined as an object of type “Vector” if it is a single
observation (temporal or not) or “VectorSeries” if it is a succession of
observations. Its availability in output is conditioned by the boolean
“Stored” associated in input.
- ObservationError
Matrix. The variable indicates the observation error covariance matrix, usually noted as
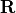 . It is defined as a “Matrix” type
object, a “ScalarSparseMatrix” type object, or a “DiagonalSparseMatrix”
type object, as described in detail in the section
Requirements to describe covariance matrices. Its availability in output is
conditioned by the boolean “Stored” associated with input.
. It is defined as a “Matrix” type
object, a “ScalarSparseMatrix” type object, or a “DiagonalSparseMatrix”
type object, as described in detail in the section
Requirements to describe covariance matrices. Its availability in output is
conditioned by the boolean “Stored” associated with input.
- ObservationOperator
Operator. The variable indicates the observation operator, usually noted as
 , which transforms the input parameters
, which transforms the input parameters  to
results
to
results  to be compared to observations
. Its value is defined as a “Function” type object or a
“Matrix” type one. In the case of “Function” type, different functional
forms can be used, as described in the section
Requirements for functions describing an operator. If there is some control
included in the observation, the operator has to be applied to a pair
.
to be compared to observations
. Its value is defined as a “Function” type object or a
“Matrix” type one. In the case of “Function” type, different functional
forms can be used, as described in the section
Requirements for functions describing an operator. If there is some control
included in the observation, the operator has to be applied to a pair
.
The general optional commands, available in the editing user graphical or textual interface, are indicated in List of commands and keywords for data assimilation or optimization case. Moreover, the parameters of the command “AlgorithmParameters” allows to choose the specific options, described hereafter, of the algorithm. See Description of options of an algorithm by “AlgorithmParameters” for the good use of this command.
The options are the following:
- Bounds
List of pairs of real values. This key allows to define pairs of upper and lower bounds for every state variable being optimized. Bounds have to be given by a list of list of pairs of lower/upper bounds for each variable, with a value of
Noneeach time there is no bound. The bounds can always be specified, but they are taken into account only by the constrained optimizers. If the list is empty, there are no bounds.Example:
{"Bounds":[[2.,5.],[1.e-2,10.],[-30.,None],[None,None]]}
- CostDecrementTolerance
Real value. This key indicates a limit value, leading to stop successfully the iterative optimization process when the cost function decreases less than this tolerance at the last step. The default is 1.e-7, and it is recommended to adapt it to the needs on real problems. One can refer to the section describing ways for Convergence control for calculation cases and iterative algorithms for more detailed recommendations.
Example:
{"CostDecrementTolerance":1.e-7}
- EstimationOf
Predefined name. This key allows to choose the type of estimation to be performed. It can be either state-estimation, with a value of “State”, or parameter-estimation, with a value of “Parameters”. The default choice is “Parameters”.
Example:
{"EstimationOf":"Parameters"}
- MaximumNumberOfFunctionEvaluations
Integer value. This key indicates the maximum number of evaluation of the cost function to be optimized. The default is 15000, which is an arbitrary limit. It is then recommended to adapt this parameter to the needs on real problems. For some optimizers, the effective number of function evaluations can be slightly different of the limit due to algorithm internal control requirements.
Example:
{"MaximumNumberOfFunctionEvaluations":50}
- MaximumNumberOfIterations
Integer value. This key indicates the maximum number of internal iterations allowed for iterative optimization. The default is 15000, which is very similar to no limit on iterations. It is then recommended to adapt this parameter to the needs on real problems. For some optimizers, the effective stopping step can be slightly different of the limit due to algorithm internal control requirements. One can refer to the section describing ways for Convergence control for calculation cases and iterative algorithms for more detailed recommendations.
Example:
{"MaximumNumberOfIterations":100}
- Minimizer
Predefined name. This key allows to choose the optimization minimizer. The default choice is “BOBYQA”, and the possible ones are “BOBYQA” (minimization, with or without constraints, by quadratic approximation, see [Powell09]), “COBYLA” (minimization, with or without constraints, by linear approximation, see [Powell94] [Powell98]). “NEWUOA” (minimization, with or without constraints, by iterative quadratic approximation, see [Powell04]), “POWELL” (minimization, unconstrained, using conjugate directions, see [Powell64]), “SIMPLEX” (minimization, with or without constraints, using Nelder-Mead simplex algorithm, see [Nelder65] and [WikipediaNM]), “SUBPLEX” (minimization, with or without constraints, using Nelder-Mead simplex algorithm on a sequence of subspaces, see [Rowan90]). Only the “POWELL” minimizer does not allow to deal with boundary constraints, all the others take them into account if they are present in the case definition.
Remark: the “POWELL” method perform a dual outer/inner loops optimization, leading then to less control on the cost function evaluation number because it is the outer loop limit than is controlled. If precise control on the evaluation number is required, choose an another minimizer.
Example:
{"Minimizer":"BOBYQA"}
- QualityCriterion
Predefined name. This key indicates the quality criterion, minimized to find the optimal state estimate. The default is the usual data assimilation criterion named “DA”, the augmented weighted least squares. The possible criterion has to be in the following list, where the equivalent names are indicated by the sign “<=>”: [“AugmentedWeightedLeastSquares” <=> “AWLS” <=> “DA”, “WeightedLeastSquares” <=> “WLS”, “LeastSquares” <=> “LS” <=> “L2”, “AbsoluteValue” <=> “L1”, “MaximumError” <=> “ME” <=> “Linf”]. See the section for Going further in the state estimation by optimization methods to have a detailed definition of these quality criteria.
Example:
{"QualityCriterion":"DA"}
- StateVariationTolerance
Real value. This key indicates the maximum relative variation of the state for stopping by convergence on the state. The default is 1.e-4, and it is recommended to adapt it to the needs on real problems.
Example:
{"StateVariationTolerance":1.e-4}- StoreSupplementaryCalculations
List of names. This list indicates the names of the supplementary variables, that can be available during or at the end of the algorithm, if they are initially required by the user. Their availability involves, potentially, costly calculations or memory consumptions. The default is then a void list, none of these variables being calculated and stored by default (excepted the unconditional variables). The possible names are in the following list (the detailed description of each named variable is given in the following part of this specific algorithmic documentation, in the sub-section “Information and variables available at the end of the algorithm”): [ “Analysis”, “BMA”, “CostFunctionJ”, “CostFunctionJb”, “CostFunctionJo”, “CostFunctionJAtCurrentOptimum”, “CostFunctionJbAtCurrentOptimum”, “CostFunctionJoAtCurrentOptimum”, “CurrentIterationNumber”, “CurrentOptimum”, “CurrentState”, “EnsembleOfSimulations”, “EnsembleOfStates”, “IndexOfOptimum”, “Innovation”, “InnovationAtCurrentState”, “OMA”, “OMB”, “SimulatedObservationAtBackground”, “SimulatedObservationAtCurrentOptimum”, “SimulatedObservationAtCurrentState”, “SimulatedObservationAtOptimum”, ].
Example :
{"StoreSupplementaryCalculations":["CurrentState", "Residu"]}
13.4.4. Information and variables available at the end of the algorithm¶
At the output, after executing the algorithm, there are information and
variables originating from the calculation. The description of
Variables and information available at the output show the way to obtain them by the method
named get, of the variable “ADD” of the post-processing in graphical
interface, or of the case in textual interface. The input variables, available
to the user at the output in order to facilitate the writing of post-processing
procedures, are described in an Inventory of potentially available information at the output.
Permanent outputs (non conditional)
The unconditional outputs of the algorithm are the following:
- Analysis
List of vectors. Each element of this variable is an optimal state
 in optimization, an interpolate or an analysis
in optimization, an interpolate or an analysis
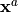 in data assimilation.
in data assimilation.Example:
xa = ADD.get("Analysis")[-1]
- CostFunctionJ
List of values. Each element is a value of the chosen error function
.Example:
J = ADD.get("CostFunctionJ")[:]
- CostFunctionJb
List of values. Each element is a value of the error function
 ,
that is of the background difference part. If this part does not exist in the
error function, its value is zero.
,
that is of the background difference part. If this part does not exist in the
error function, its value is zero.Example:
Jb = ADD.get("CostFunctionJb")[:]
- CostFunctionJo
List of values. Each element is a value of the error function
 ,
that is of the observation difference part.
,
that is of the observation difference part.Example:
Jo = ADD.get("CostFunctionJo")[:]
- CurrentState
List of vectors. Each element is a usual state vector used during the iterative algorithm procedure.
Example:
xs = ADD.get("CurrentState")[:]
Set of on-demand outputs (conditional or not)
The whole set of algorithm outputs (conditional or not), sorted by alphabetical order, is the following:
- Analysis
List of vectors. Each element of this variable is an optimal state
in optimization, an interpolate or an analysis
in data assimilation.Example:
xa = ADD.get("Analysis")[-1]
- BMA
List of vectors. Each element is a vector of difference between the background and the optimal state.
Example:
bma = ADD.get("BMA")[-1]
- CostFunctionJ
List of values. Each element is a value of the chosen error function
.Example:
J = ADD.get("CostFunctionJ")[:]
- CostFunctionJb
List of values. Each element is a value of the error function
,
that is of the background difference part. If this part does not exist in the
error function, its value is zero.Example:
Jb = ADD.get("CostFunctionJb")[:]
- CostFunctionJo
List of values. Each element is a value of the error function
,
that is of the observation difference part.Example:
Jo = ADD.get("CostFunctionJo")[:]
- CostFunctionJAtCurrentOptimum
List of values. Each element is a value of the error function
.
At each step, the value corresponds to the optimal state found from the
beginning.Example:
JACO = ADD.get("CostFunctionJAtCurrentOptimum")[:]
- CostFunctionJbAtCurrentOptimum
List of values. Each element is a value of the error function
. At
each step, the value corresponds to the optimal state found from the
beginning. If this part does not exist in the error function, its value is
zero.Example:
JbACO = ADD.get("CostFunctionJbAtCurrentOptimum")[:]
- CostFunctionJoAtCurrentOptimum
List of values. Each element is a value of the error function
,
that is of the observation difference part. At each step, the value
corresponds to the optimal state found from the beginning.Example:
JoACO = ADD.get("CostFunctionJoAtCurrentOptimum")[:]
- CurrentIterationNumber
List of integers. Each element is the iteration index at the current step during the iterative algorithm procedure. There is one iteration index value per assimilation step corresponding to an observed state.
Example:
cin = ADD.get("CurrentIterationNumber")[-1]
- CurrentOptimum
List of vectors. Each element is the optimal state obtained at the usual step of the iterative algorithm procedure of the optimization algorithm. It is not necessarily the last state.
Example:
xo = ADD.get("CurrentOptimum")[:]
- CurrentState
List of vectors. Each element is a usual state vector used during the iterative algorithm procedure.
Example:
xs = ADD.get("CurrentState")[:]
- EnsembleOfSimulations
List of vectors or matrix. This key contains an ordered collection of physical state vectors or simulated state vectors
that may
be observed. These are operator outputs, i.e. simulated
observation states (called “snapshots” in reduced-base terminology). At
each step index, there is 1 state per column if this list is in matrix form,
or 1 state per element if it’s actually a list. Caution: the numbering of the
support or points, on which or to which a state value is given in each
vector, is implicitly that of the natural order of numbering of the state
vector, from 0 to the “size minus 1” of this vector.Example :
{"EnsembleOfSimulations":[y1, y2, y3...]}
- EnsembleOfStates
List of vectors or matrix. Each element is an ordered collection of physical or parameter state vectors
. These are
operator entries, i.e. current states before observation. At each step
index, there is 1 state per column if this list is in matrix form, or 1 state
per element if it’s actually a list. Caution: the numbering of the support or
points, on which or to which a state value is given in each vector, is
implicitly that of the natural order of numbering of the state vector, from 0
to the “size minus 1” of this vector.Example :
{"EnsembleOfStates":[x1, x2, x3...]}
- IndexOfOptimum
List of integers. Each element is the iteration index of the optimum obtained at the current step of the iterative algorithm procedure of the optimization algorithm. It is not necessarily the number of the last iteration.
Example:
ioo = ADD.get("IndexOfOptimum")[-1]
- Innovation
List of vectors. Each element is an innovation vector, which is in static the difference between the optimal and the background, and in dynamic the evolution increment.
Example:
d = ADD.get("Innovation")[-1]
- InnovationAtCurrentState
List of vectors. Each element is an innovation vector at current state before analysis.
Example:
ds = ADD.get("InnovationAtCurrentState")[-1]
- OMA
List of vectors. Each element is a vector of difference between the observation and the optimal state in the observation space.
Example:
oma = ADD.get("OMA")[-1]
- OMB
List of vectors. Each element is a vector of difference between the observation and the background state in the observation space.
Example:
omb = ADD.get("OMB")[-1]
- SimulatedObservationAtBackground
List of vectors. Each element is a vector of observation simulated by the observation operator from the background
. It is the
forecast from the background, and it is sometimes called “Dry”.Example:
hxb = ADD.get("SimulatedObservationAtBackground")[-1]
- SimulatedObservationAtCurrentOptimum
List of vectors. Each element is a vector of observation simulated from the optimal state obtained at the current step the optimization algorithm, that is, in the observation space.
Example:
hxo = ADD.get("SimulatedObservationAtCurrentOptimum")[-1]
- SimulatedObservationAtCurrentState
List of vectors. Each element is an observed vector simulated by the observation operator from the current state, that is, in the observation space.
Example:
hxs = ADD.get("SimulatedObservationAtCurrentState")[-1]
- SimulatedObservationAtOptimum
List of vectors. Each element is a vector of observation obtained by the observation operator from simulation on the analysis or optimal state
. It is the observed forecast from the analysis or the
optimal state, and it is sometimes called “Forecast”.Example:
hxa = ADD.get("SimulatedObservationAtOptimum")[-1]
13.4.5. Python (TUI) use examples¶
Here is one or more very simple examples of the proposed algorithm and its parameters, written in [DocR] Textual User Interface for ADAO (TUI/API). Moreover, when it is possible, the information given as input also allows to define an equivalent case in [DocR] Graphical User Interface for ADAO (GUI/EFICAS).
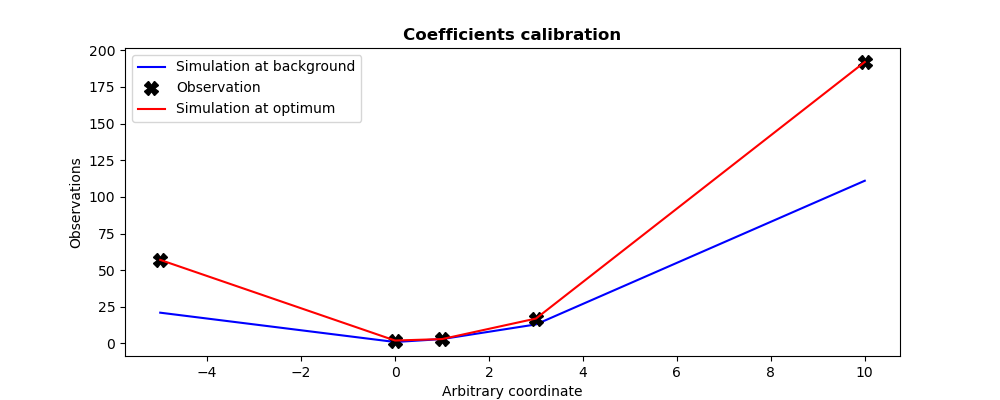
This example describes the calibration of parameters of a
quadratic observation model . This model is here represented as a
function named QuadFunction. This function get as input the coefficients
vector , and return as output the evaluation vector
of the quadratic model at the predefined internal control
points. The calibration is done using an initial coefficient set (background
state specified by Xb in the code), and with the information
(specified by Yobs in the code) of 5 measures obtained
in these same internal control points. We set twin experiments (see
To test a data assimilation chain: the twin experiments) and the measurements are supposed to be
perfect. We choose to emphasize the observations versus the background by
setting a great variance for the background error, here of  .
.
The adjustment is carried out by displaying intermediate results during iterative optimization.
# -*- coding: utf-8 -*-
#
from numpy import array, ravel
def QuadFunction( coefficients ):
"""
Quadratic simulation in x points: y = a x^2 + b x + c
"""
a, b, c = list(ravel(coefficients))
x_points = (-5, 0, 1, 3, 10)
y_points = []
for x in x_points:
y_points.append( a*x*x + b*x + c )
return array(y_points)
#
Xb = array([1., 1., 1.])
Yobs = array([57, 2, 3, 17, 192])
#
print("Resolution of the calibration problem")
print("-------------------------------------")
print("")
from adao import adaoBuilder
case = adaoBuilder.New()
case.setBackground( Vector = Xb, Stored=True )
case.setBackgroundError( ScalarSparseMatrix = 1.e6 )
case.setObservation( Vector = Yobs, Stored=True )
case.setObservationError( ScalarSparseMatrix = 1. )
case.setObservationOperator( OneFunction = QuadFunction )
case.setAlgorithmParameters(
Algorithm="DerivativeFreeOptimization",
Parameters={
"MaximumNumberOfIterations": 100,
"StoreSupplementaryCalculations": [
"CurrentState",
],
},
)
case.setObserver(
Info=" Intermediate state at the current iteration:",
Template="ValuePrinter",
Variable="CurrentState",
)
case.execute()
print("")
#
#-------------------------------------------------------------------------------
#
print("Calibration of %i coefficients in a 1D quadratic function on %i measures"%(
len(case.get("Background")),
len(case.get("Observation")),
))
print("----------------------------------------------------------------------")
print("")
print("Observation vector.................:", ravel(case.get("Observation")))
print("A priori background state..........:", ravel(case.get("Background")))
print("")
print("Expected theoretical coefficients..:", ravel((2,-1,2)))
print("")
print("Number of iterations...............:", len(case.get("CurrentState")))
print("Number of simulations..............:", len(case.get("CurrentState")))
print("Calibration resulting coefficients.:", ravel(case.get("Analysis")[-1]))
#
Xa = case.get("Analysis")[-1]
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (10, 4)
#
plt.figure()
plt.plot((-5,0,1,3,10),QuadFunction(Xb),"b--",label="Simulation at background")
plt.plot((-5,0,1,3,10),Yobs, "kX", label="Observation",markersize=10)
plt.plot((-5,0,1,3,10),QuadFunction(Xa),"r-", label="Simulation at optimum")
plt.legend()
plt.title("Coefficients calibration", fontweight="bold")
plt.xlabel("Arbitrary coordinate")
plt.ylabel("Observations")
plt.savefig("simple_DerivativeFreeOptimization.png")
The execution result is the following:
Resolution of the calibration problem
-------------------------------------
Intermediate state at the current iteration: [1. 1. 1.]
Intermediate state at the current iteration: [2. 1. 1.]
Intermediate state at the current iteration: [1. 2. 1.]
Intermediate state at the current iteration: [1. 1. 2.]
Intermediate state at the current iteration: [0. 1. 1.]
Intermediate state at the current iteration: [1. 0. 1.]
Intermediate state at the current iteration: [1. 1. 0.]
Intermediate state at the current iteration: [1.82475484 1.96682811 1.18582936]
Intermediate state at the current iteration: [1.89559338 0.54235283 1.17221593]
Intermediate state at the current iteration: [ 1.90222657 -0.20823061 1.83295831]
Intermediate state at the current iteration: [ 1.94478151 -0.55541624 2.76978872]
Intermediate state at the current iteration: [ 2.04021458 -1.49397981 2.43813988]
Intermediate state at the current iteration: [ 2.26677171 -0.58498556 2.84248383]
Intermediate state at the current iteration: [ 1.9902328 -1.04021448 2.88338819]
Intermediate state at the current iteration: [ 1.98695318 -0.92116383 2.47695648]
Intermediate state at the current iteration: [ 1.99320312 -1.02368518 2.64731215]
Intermediate state at the current iteration: [ 1.79473809 -0.96379959 2.44856121]
Intermediate state at the current iteration: [ 1.98630908 -0.91207212 2.5394595 ]
Intermediate state at the current iteration: [ 1.99262279 -0.97073591 2.4801914 ]
Intermediate state at the current iteration: [ 1.99434434 -0.99814626 2.51840027]
Intermediate state at the current iteration: [ 1.98838712 -0.93500739 2.44986416]
Intermediate state at the current iteration: [ 1.99080633 -0.94768294 2.46780354]
Intermediate state at the current iteration: [ 2.01588592 -0.97086338 2.47667529]
Intermediate state at the current iteration: [ 1.99098142 -0.96519905 2.48111896]
Intermediate state at the current iteration: [ 1.99157918 -0.97086422 2.47290017]
Intermediate state at the current iteration: [ 1.9929175 -0.98359308 2.45753186]
Intermediate state at the current iteration: [ 1.99550241 -1.01497755 2.43286745]
Intermediate state at the current iteration: [ 1.99505414 -1.00691754 2.44681334]
Intermediate state at the current iteration: [ 1.97993261 -1.01100857 2.43408454]
Intermediate state at the current iteration: [ 1.99503312 -1.0022575 2.42298652]
Intermediate state at the current iteration: [ 1.99337049 -0.98139127 2.3984825 ]
Intermediate state at the current iteration: [ 1.99387512 -0.97303786 2.33457311]
Intermediate state at the current iteration: [ 1.99742055 -0.99371791 2.20738214]
Intermediate state at the current iteration: [ 2.0002882 -0.98541744 1.96740743]
Intermediate state at the current iteration: [ 2.00047429 -0.99646137 2.01501424]
Intermediate state at the current iteration: [ 2.0009106 -1.00072301 2.00881512]
Intermediate state at the current iteration: [ 1.9909278 -1.00127001 2.00860374]
Intermediate state at the current iteration: [ 2.0009174 -1.00688459 2.01669134]
Intermediate state at the current iteration: [ 1.99994608 -1.00029476 2.00923274]
Intermediate state at the current iteration: [ 2.00031465 -1.00202777 1.98931137]
Intermediate state at the current iteration: [ 1.99389877 -1.00336389 2.01658192]
Intermediate state at the current iteration: [ 2.00003478 -1.00017674 1.99950089]
Intermediate state at the current iteration: [ 1.99970222 -0.99882654 1.99924329]
Intermediate state at the current iteration: [ 2.00000228 -0.99960552 1.99820757]
Intermediate state at the current iteration: [ 2.00103142 -1.0000571 1.9985047 ]
Intermediate state at the current iteration: [ 1.99925894 -1.0009752 1.9986288 ]
Intermediate state at the current iteration: [ 1.99998604 -0.99994926 2.00089583]
Intermediate state at the current iteration: [ 2.00000344 -0.99996363 1.9994818 ]
Intermediate state at the current iteration: [ 1.99980383 -0.99996386 1.9994693 ]
Intermediate state at the current iteration: [ 1.99998362 -0.99985392 1.99931575]
Intermediate state at the current iteration: [ 2.00000605 -1.00001563 1.9996749 ]
Intermediate state at the current iteration: [ 2.00000343 -1.00002045 1.99987483]
Intermediate state at the current iteration: [ 2.00000165 -1.0000257 2.00006119]
Intermediate state at the current iteration: [ 2.00000167 -1.00001085 1.99996478]
Calibration of 3 coefficients in a 1D quadratic function on 5 measures
----------------------------------------------------------------------
Observation vector.................: [ 57. 2. 3. 17. 192.]
A priori background state..........: [1. 1. 1.]
Expected theoretical coefficients..: [ 2 -1 2]
Number of iterations...............: 54
Number of simulations..............: 54
Calibration resulting coefficients.: [ 2.00000167 -1.00001085 1.99996478]
The figures illustrating the result of its execution are as follows: