15.3. Algorithme de tâche « MeasurementsOptimalPositioningTask »¶
Cet algorithme est réservé à une utilisation en interface textuelle (TUI), et donc pas en interface graphique (GUI).
15.3.1. Description¶
Cet algorithme permet d’établir la position optimale de mesures d’un champ
physique  , pour en assurer l’interpolation la meilleure
possible. Ces positions optimales de mesure sont déterminées de manière
itérative, à partir d’un ensemble de vecteurs d’état
pré-existants (usuellement appelés « snapshots » en méthodologie de bases
réduites) ou obtenus par une simulation de ce(s) champ(s) physiqu(e) d’intérêt
au cours de l’algorithme. Chacun de ces vecteurs d’état est habituellement
(mais pas obligatoirement) le résultat d’une simulation à
l’aide de l’opérateur
, pour en assurer l’interpolation la meilleure
possible. Ces positions optimales de mesure sont déterminées de manière
itérative, à partir d’un ensemble de vecteurs d’état
pré-existants (usuellement appelés « snapshots » en méthodologie de bases
réduites) ou obtenus par une simulation de ce(s) champ(s) physiqu(e) d’intérêt
au cours de l’algorithme. Chacun de ces vecteurs d’état est habituellement
(mais pas obligatoirement) le résultat d’une simulation à
l’aide de l’opérateur  restituant le (ou les) champ(s) complet(s) pour
un jeu de paramètres donné
restituant le (ou les) champ(s) complet(s) pour
un jeu de paramètres donné  , ou d’une observation explicite
du (ou des) champ(s) complet(s) .
, ou d’une observation explicite
du (ou des) champ(s) complet(s) .
Pour établir la position optimale de mesures, on utilise une méthode de type
Empirical Interpolation Method (EIM [Barrault04]) ou Discrete Empirical
Interpolation Method (DEIM [Chaturantabut10]), qui établit un modèle réduit de
type Reduced Order Model (ROM), avec contraintes (variante « lcEIM » ou
« lcDEIM ») ou sans contraintes (variante « EIM » ou « DEIM ») de
positionnement. Techniquement, ces méthodes permettent de construire une
approximation de l’état dans un espace de dimension réduite,
en utilisant un ensemble de points spéciaux d’interpolation pour représenter de
manière optimale le comportement global du champ . Pour la
performance, il est recommandé d’utiliser la variante « lcEIM » ou « EIM »
lorsque la dimension de l’espace des champs complets est grande.
Il y a deux manières d’utiliser cet algorithme:
Dans son usage le plus simple, si l’ensemble des vecteurs d’état physique
est pré-existant, il suffit de le fournir sous la forme
d’une collection ordonnée par l’option « EnsembleOfSnapshots » de
l’algorithme. C’est par exemple ce que l’on obtient par défaut si l’ensemble
des états a été généré par un
Algorithme de tâche « EnsembleOfSimulationGenerationTask ».Si l’ensemble des vecteurs d’état physique
doit être
obtenu par des simulations explicites au cours de l’algorithme, alors on
doit fournir à la fois l’opérateur de simulation du champ complet, ici
identifié à l’opérateur d’observation du champ complet, et le plan
d’expérience de l’espace des états paramétriques.
Dans le cas où l’on fournit le plan d’expérience, l’échantillonnage des états
peut être fourni comme pour un
Algorithme de tâche « EnsembleOfSimulationGenerationTask », explicitement
ou sous la forme d’hypercubes, explicites ou échantillonnés selon des
distributions courantes, ou à l’aide d’un échantillonnage par hypercube latin
(LHS) ou par séquence de Sobol. Les calculs sont optimisés selon les ressources
informatiques disponibles et les options demandées par l’utilisateur. On pourra
se reporter aux Conditions requises pour décrire un échantillonnage d’états pour une illustration
de l’échantillonnage. Attention à la taille de l’hypercube (et donc au nombre
de calculs) qu’il est possible d’atteindre, elle peut rapidement devenir
importante. La mémoire requise est ensuite le produit de la taille d’un état
individuel par la taille de l’hypercube.

Schéma général d’utilisation de l’algorithme
Il est possible d’exclure a priori des positions potentielles pour le positionnement des mesures, en utilisant le variant « lcEIM » ou « lcDEIM » d’analyse pour une recherche de positionnement contraint.
15.3.2. Quelques propriétés notables des méthodes implémentées¶
Pour compléter la description on synthétise ici quelques propriétés notables, des méthodes de l’algorithme ou de leurs implémentations. Ces propriétés peuvent avoir une influence sur la manière de l’utiliser ou sur ses performances de calcul. Pour de plus amples renseignements, on se reportera aux références plus complètes indiquées à la fin du descriptif de cet algorithme.
Les méthodes proposées par cet algorithme ne requièrent pas de dérivation de la fonction objectif ou de l’un des opérateurs, permettant d’éviter ce temps de calcul supplémentaire dans le cas où les dérivées sont calculées numériquement par de multiples évaluations.
Les méthodes proposées par cet algorithme présentent un parallélisme interne, et peuvent donc profiter de ressources informatiques de répartition de calculs. L’interaction potentielle, entre le parallélisme interne des méthodes, et le parallélisme éventuellement présent dans les opérateurs d’observation ou d’évolution intégrant les codes de l’utilisateur, doit donc être soigneusement réglée.
15.3.3. Commandes requises et optionnelles¶
Les commandes générales requises, disponibles en édition dans l’interface graphique ou textuelle, sont les suivantes :
Aucune
Les commandes optionnelles générales, disponibles en édition dans l’interface graphique ou textuelle, sont indiquées dans la Liste des commandes et mots-clés pour un cas orienté tâche ou étude dédiée. De plus, les paramètres de la commande « AlgorithmParameters » permettent d’indiquer les options particulières, décrites ci-après, de l’algorithme. On se reportera à la Description des options d’un algorithme par « AlgorithmParameters » pour le bon usage de cette commande.
Les options sont les suivantes :
- EnsembleOfSnapshots
Liste de vecteurs ou matrice. Cette clé contient une collection ordonnée de vecteurs d’état physique
, nommés « snapshots » en
terminologie de bases réduites. A chaque index de pas, il y a 1 état par
colonne si cette liste est sous forme matricielle, ou 1 état par élément si
c’est effectivement une liste. Important : la numérotation du support ou des
points, sur lequel ou auxquels sont fournis une valeur d’état dans chaque
vecteur, est implicitement celle de l’ordre naturel de numérotation du
vecteur d’état, de 0 à la « taille moins 1 » de ce vecteur.Exemple :
{"EnsembleOfSnapshots":[y1, y2, y3...]}
- ExcludeLocations
Liste d’entiers ou de noms. Cette clé indique la liste des points du vecteur d’état exclus de la recherche optimale. La valeur par défaut est une liste vide. La liste peut contenir soit des indices de points (dans l’ordre interne implicite d’un vecteur d’état), soit des noms des points (qui doivent exister dans la liste des noms de positions indiquées par le mot-clé « NameOfLocations » pour pouvoir être exclus). Par défaut, si les éléments de la liste sont des chaînes de caractères assimilables à des indices, alors ces chaînes sont bien considérées comme des indices et pas des noms.
Rappel important : la numérotation de ces points exclus doit être identique à celle qui est adoptée, implicitement et impérativement, par les variables constituant un état considéré arbitrairement sous forme unidimensionnelle.
Exemple :
{"ExcludeLocations":[3, 125, 286]}ou{"ExcludeLocations":["Point3", "XgTaC"]}
- ErrorNorm
Nom prédéfini. Cette clé indique la norme utilisée pour le résidu qui contrôle la recherche optimale. Le défaut est la norme « L2 ». Les critères possibles sont dans la liste suivante : [« L2 », « Linf »].
Exemple :
{"ErrorNorm":"L2"}
- ErrorNormTolerance
Valeur réelle. Cette clé indique la valeur à partir laquelle le résidu associé à l’approximation est acceptable, ce qui conduit à arrêter la recherche optimale. La valeur par défaut est de 1.e-7 (ce qui équivaut usuellement à une quasi-absence de critère d’arrêt car l’approximation est moins précise), et il est recommandé de l’adapter aux besoins pour des problèmes réels. Une valeur habituelle, recommandée pour arrêter la recherche sur critère de résidu, est de 1.e-2.
Exemple :
{"ErrorNormTolerance":1.e-7}
- MaximumNumberOfLocations
Valeur entière. Cette clé indique le nombre maximum possible de positions trouvées dans la recherche optimale. La valeur par défaut est 1. La recherche optimale peut éventuellement trouver moins de positions que ce qui est requis par cette clé, comme par exemple dans le cas où le résidu associé à l’approximation est inférieur au critère et conduit à l’arrêt anticipé de la recherche optimale. Il est recommandé de l’adapter aux besoins pour des problèmes réels.
Exemple :
{"MaximumNumberOfLocations":5}
- NameOfLocations
Liste de noms. Cette clé indique une liste explicite de noms des variables ou de positions, positionnées comme dans un vecteur d’état considéré arbitrairement sous forme unidimensionnelle. La valeur par défaut est une liste vide. Pour être utilisée, cette liste doit avoir la même longueur que celle d’un état physique.
Rappel important : l’ordre des noms est, implicitement et impérativement, le même que celui des variables constituant un état considéré arbitrairement sous forme unidimensionnelle.
Exemple :
{"NameOfLocations":["Point3", "Location42", "Position125", "XgTaC"]}
- ReduceMemoryUse
Valeur booléenne. La variable conduit à l’activation, ou pas, du mode de réduction de l’empreinte mémoire lors de l’exécution, au prix d’une augmentation potentielle du temps de calcul. Les résultats peuvent différer à partir d’une certaine précision (1.e-12 à 1.e-14) usuellement proche de la précision machine (1.e-16). La valeur par défaut est « False », les choix sont « True » ou « False ».
Exemple :
{"ReduceMemoryUse":False}
- SampleAsExplicitHyperCube
Liste de liste de valeurs réelles. Cette clé décrit les points de calcul sous la forme d’un hyper-cube, dont on donne la liste des échantillonnages explicites de chaque variable comme une liste. C’est donc une liste de listes, chacune étant de taille potentiellement différente. Par nature, les points sont inclus dans le domaine défini par les bornes des listes explicites de chaque variable.
Exemple :
{"SampleAsExplicitHyperCube":[[0.,0.25,0.5,0.75,1.], [-2,2,1]]}pour un espace d’état de dimension 2.
- SampleAsIndependentRandomVariables
Liste de triplets [Nom, Paramètres, Nombre]. Cette clé décrit les points de calcul sous la forme d’un hyper-cube, dont les points sur chaque axe proviennent de l’échantillonnage aléatoire indépendant de la variable d’axe, selon la spécification de la distribution, de ses paramètres et du nombre de points de l’échantillon, sous la forme d’une liste [Nom, Paramètres, Nombre] pour chaque axe. Contrairement à l’échantillonnage décrit par le mot-clé « SampleAsIndependentRandomVectors » , les points sont explicitement répartis sur un hypercube régulier. Les noms de distributions possibles sont “normal” de paramètres (mean,std), “lognormal” de paramètres (mean,sigma), “uniform” de paramètres (low,high), “loguniform” de paramètres (low,high), ou “weibull” de paramètre (shape). C’est donc une liste de la même taille que celle de l’état. Par nature, les points sont inclus dans le domaine non borné ou borné selon les caractéristiques des distributions choisies par variable. Les distributions peuvent être différentes pour chaque axe.
Exemple :
{"SampleAsIndependentRandomVariables":[['normal',[0.,1.],3], ['uniform',[-2,2],4]]}pour un espace d’état de dimension 2.
- SampleAsIndependentRandomVectors
Liste de paires [Nom, Paramètres], plus [Dimension, Nombre]. Cette clé décrit les points de calcul sous la forme de distributions particulières définies pour chaque dimension, qui permettent d’obtenir des vecteurs aléatoires dont chaque composante suit la distribution requise. Contrairement à l’échantillonnage décrit par le mot-clé « SampleAsIndependentRandomVariables » , les points ne sont pas répartis sur un hypercube régulier. La distribution sur chaque variable d’axe et spécifiée par non nom et ses paramètres, sous la forme d’une liste [Nom, Paramètres] pour chaque axe. Cette liste de paires, en nombre identique à la taille de l’espace des états, est complétée par une paire d’entiers [Dimension, Nombre] comportant la dimension de l’espace des états et le nombre souhaité de points d’échantillonnage. Les noms de distributions possibles sont “normal” de paramètres (mean,std), “lognormal” de paramètres (mean,sigma), “uniform” de paramètres (low,high), “loguniform” de paramètres (low,high), ou “weibull” de paramètre (shape). Par nature, les points sont inclus dans le domaine non borné ou borné selon les caractéristiques des distributions choisies par variable. Les distributions peuvent être différentes pour chaque axe.
Exemple :
{"SampleAsIndependentRandomVectors":[['normal',[0.,1.]], ['uniform',[-2,2]]]}pour un espace d’état de dimension 2.
- SampleAsMinMaxLatinHyperCube
Liste de paires réelles [Min, Max], plus [Dimension, Nombre]. Cette clé décrit le domaine borné dans lequel les points de calcul seront placés, sous la forme d’une paire [Min, Max] pour chaque composante de l’état. Les bornes inférieures sont incluses. Cette liste de paires, en nombre identique à la taille de l’espace des états, est complétée par une paire d’entiers [Dimension, Nombre] comportant la dimension de l’espace des états et le nombre souhaité de points d’échantillonnage. L’échantillonnage est ensuite construit automatiquement selon la méthode de l’hypercube Latin (LHS). Par nature, les points sont inclus dans le domaine défini par les bornes explicites.
Exemple :
{"SampleAsMinMaxLatinHyperCube":[[0.,1.],[-1,3]]+[[2,11]]}pour un espace d’état de dimension 2 et pour 11 points d’échantillonnage.
- SampleAsMinMaxSobolSequence
Liste de paires réelles [Min, Max], plus [Dimension, Nombre]. Cette clé décrit le domaine borné dans lequel les points de calcul seront placés, sous la forme d’une paire [Min, Max] pour chaque composante de l’état. Les bornes inférieures sont incluses. Cette liste de paires, en nombre identique à la taille de l’espace des états, est complétée par une paire d’entiers [Dimension, Nombre] comportant la dimension de l’espace des états et le nombre minimum souhaité de points d’échantillonnage (par construction, le nombre de points générés dans la séquence de Sobol sera la puissance de 2 immédiatement supérieure à ce nombre minimum). L’échantillonnage est ensuite construit automatiquement selon la méthode de séquences de Sobol. Par nature, les points sont inclus dans le domaine défini par les bornes explicites.
Remarque : il est nécessaire de disposer de Scipy en version supérieure à 1.7.0 pour utiliser cette option échantillonnage.
Exemple :
{"SampleAsMinMaxSobolSequence":[[0.,1.],[-1,3]]+[[2,11]]}pour un espace d’état de dimension 2 et au moins 11 points d’échantillonnage (il y aura 16 points en pratique).
- SampleAsMinMaxStepHyperCube
Liste de triplets de valeurs réelles [Min, Max, Step]. Cette clé décrit les points de calcul sous la forme d’un hyper-cube, dont on donne la liste des échantillonnages implicites de chaque variable par un triplet [Min, Max, Step]. C’est donc une liste de la même taille que celle de l’état. Les bornes sont incluses. Par nature, les points sont inclus dans le domaine défini par les bornes explicites.
Exemple :
{"SampleAsMinMaxStepHyperCube":[[0.,1.,0.25],[-1,3,1]]}pour un espace d’état de dimension 2.
- SampleAsnUplet
Liste d’états. Cette clé décrit les points de calcul sous la forme d’une liste de n-uplets, chaque n-uplet étant un état. Par nature, les points sont inclus dans le domaine borné défini comme l’enveloppe convexe des points explicitement désignés.
Exemple :
{"SampleAsnUplet":[[0,1,2,3],[4,3,2,1],[-2,3,-4,5]]}pour 3 points dans un espace d’état de dimension 4.
- SetDebug
Valeur booléenne. La variable conduit à l’activation, ou pas, du mode de débogage durant l’évaluation de la fonction ou de l’opérateur. La valeur par défaut est « False », les choix sont « True » ou « False ».
Exemple :
{"SetDebug":False}
- SetSeed
Valeur entière. Cette clé permet de donner un nombre entier pour fixer la graine du générateur aléatoire utilisé dans l’algorithme. Par défaut, la graine est laissée non initialisée, et elle utilise ainsi l’initialisation par défaut de l’ordinateur, qui varie donc à chaque étude. Pour assurer la reproductibilité de résultats impliquant des tirages aléatoires, il est fortement conseillé d’initialiser la graine. Une valeur simple est par exemple 123456789. Il est conseillé de mettre un entier à plus de 6 ou 7 chiffres pour bien initialiser le générateur aléatoire.
Exemple :
{"SetSeed":123456789}- StoreSupplementaryCalculations
Liste de noms. Cette liste indique les noms des variables supplémentaires, qui peuvent être disponibles au cours du déroulement ou à la fin de l’algorithme, si elles sont initialement demandées par l’utilisateur. Leur disponibilité implique, potentiellement, des calculs ou du stockage coûteux. La valeur par défaut est donc une liste vide, aucune de ces variables n’étant calculée et stockée par défaut (sauf les variables inconditionnelles). Les noms possibles pour les variables supplémentaires sont dans la liste suivante (la description détaillée de chaque variable nommée est donnée dans la suite de cette documentation par algorithme spécifique, dans la sous-partie « Informations et variables disponibles à la fin de l’algorithme ») : [ « EnsembleOfSimulations », « EnsembleOfStates », « ExcludedPoints », « OptimalPoints », « ReducedBasis », « ReducedBasisMus », « Residus », « SingularValues », ].
Exemple :
{"StoreSupplementaryCalculations":["CurrentState", "Residu"]}
- Variant
Nom prédéfini. Cette clé permet de choisir l’une des variantes possibles pour la recherche du positionnement optimal. La variante par défaut est la version contrainte par des positions exclues « lcEIM » ou « PositioningBylcEIM », et les choix possibles sont « EIM » ou « PositioningByEIM » (utilisant l’algorithme EIM original), « lcEIM » ou « PositioningBylcEIM » (utilisant l’algorithme EIM contraint par des positions exclues, nommé « Location Constrained EIM »), « DEIM » ou « PositioningByDEIM » (utilisant l’algorithme DEIM original), « lcDEIM » ou « PositioningBylcDEIM » (utilisant l’algorithme DEIM contraint par des positions exclues, nommé « Location Constrained DEIM »). Il est fortement recommandé de conserver la valeur par défaut.
Exemple :
{"Variant":"lcEIM"}
15.3.4. Informations et variables disponibles à la fin de l’algorithme¶
En sortie, après exécution de l’algorithme, on dispose d’informations et de
variables issues du calcul. La description des
Variables et informations disponibles en sortie indique la manière de les obtenir, par la
méthode nommée get, depuis la variable « ADD » du post-processing en
interface graphique, ou depuis le cas en interface textuelle. Les variables
d’entrée, mises à disposition de l’utilisateur en sortie pour faciliter
l’écriture des procédures de post-processing, sont décrites dans un
Inventaire des informations potentiellement disponibles en sortie.
Sorties permanentes (non conditionnelles)
Les sorties non conditionnelles de l’algorithme sont les suivantes :
- OptimalPoints
Liste de série d’entiers. Chaque élément est une série, contenant les indices des positions idéales ou points optimaux auxquels une mesure est requise, déterminés par la recherche optimale, rangés par ordre de préférence décroissante et dans le même ordre que les vecteurs trouvés itérativement pour constituer la base réduite.
Exemple :
op = ADD.get("OptimalPoints")[-1]
Ensemble des sorties à la demande (conditionnelles ou non)
L’ensemble des sorties (conditionnelles ou non) de l’algorithme, classées par ordre alphabétique, est le suivant :
- EnsembleOfSimulations
Liste de vecteurs ou matrice. Chaque élément est une collection ordonnée de vecteurs d’état physique ou d’état simulé éventuellement observé
. Ce sont des sorties d’opérateur ,
c’est-à-dire des états d’observation simulés (nommés « snapshots » en
terminologie de bases réduites). A chaque index de pas, il y a 1 état par
colonne si cette liste est sous forme matricielle, ou 1 état par élément si
c’est effectivement une liste. Important : la numérotation du support ou des
points, sur lequel ou auxquels sont fournis une valeur d’état dans chaque
vecteur, est implicitement celle de l’ordre naturel de numérotation du
vecteur d’état, de 0 à la « taille moins 1 » de ce vecteur.Exemple :
{"EnsembleOfSimulations":[y1, y2, y3...]}
- EnsembleOfStates
Liste de vecteurs ou matrice. Chaque élément est une collection ordonnée de vecteurs d’état physique ou d’état paramétrique
. Ce sont
des entrées d’opérateur , c’est-à-dire des états courants avant
observation. A chaque index de pas, il y a 1 état par colonne si cette liste
est sous forme matricielle, ou 1 état par élément si c’est effectivement une
liste. Important : la numérotation du support ou des points, sur lequel ou
auxquels sont fournis une valeur d’état dans chaque vecteur, est
implicitement celle de l’ordre naturel de numérotation du vecteur d’état, de
0 à la « taille moins 1 » de ce vecteur.Exemple :
{"EnsembleOfStates":[x1, x2, x3...]}
- ExcludedPoints
Liste de série d’entiers. Chaque élément est une série, contenant les indices des points exclus de la recherche optimale, selon l’ordre des variables d’un vecteur d’état considéré arbitrairement sous forme unidimensionnelle.
Exemple :
ep = ADD.get("ExcludedPoints")[-1]
- OptimalPoints
Liste de série d’entiers. Chaque élément est une série, contenant les indices des positions idéales ou points optimaux auxquels une mesure est requise, déterminés par la recherche optimale, rangés par ordre de préférence décroissante et dans le même ordre que les vecteurs trouvés itérativement pour constituer la base réduite.
Exemple :
op = ADD.get("OptimalPoints")[-1]
- ReducedBasis
Liste de matrices. Chaque élément est une matrice, contenant dans chaque colonne un vecteur de la base réduite obtenue par la recherche optimale, rangés par ordre de préférence décroissante, et dans le même ordre que les points idéaux trouvés itérativement.
Lorsque c’est une donnée d’entrée, elle est identique à une sortie unique d’un Algorithme de tâche « MeasurementsOptimalPositioningTask ».
Exemple :
rb = ADD.get("ReducedBasis")[-1]
- ReducedBasisMus
Liste de série d’entiers. Chaque élément est une série, contenant les indices des paramètres
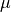 caractérisant un état, dans l’ordre choisi
lors de la recherche itérative des vecteurs de la base réduite.
caractérisant un état, dans l’ordre choisi
lors de la recherche itérative des vecteurs de la base réduite.Exemple :
op = ADD.get("ReducedBasisMus")[-1]
- Residus
Liste de série de valeurs réelles. Chaque élément est une série, contenant les valeurs du résidu particulier vérifié lors du déroulement de l’algorithme.
Exemple :
rs = ADD.get("Residus")[-1]
- SingularValues
Liste de série de valeurs réelles. Chaque élément est une série, contenant les valeurs singulières obtenues par une décomposition SVD d’un ensemble de vecteurs d’états complets. Le nombre de valeurs singulières retenues n’est pas limité par la taille de la base réduite demandée.
Exemple :
sv = ADD.get("SingularValues")[-1]
15.3.5. Exemples d’utilisation en Python (TUI)¶
Voici un ou des exemples très simple d’usage de l’algorithme proposé et de ses paramètres, écrit en [DocR] Interface textuelle pour l’utilisateur (TUI/API). De plus, lorsque c’est possible, les informations indiquées en entrée permettent aussi de définir un cas équivalent en interface graphique [DocR] Interface graphique pour l’utilisateur (GUI/EFICAS).
15.3.5.1. Premier exemple¶
Cet exemple décrit la mise en oeuvre d’une recherche de positionnement optimal de mesures. Pour l’illustration, on construit une collection artificielle de champs physiques très simple (engendré ici de manière à exister dans un espace vectoriel de dimension 2). La recherche ADAO par défaut permet ensuite d’obtenir aisément 2 positions optimales pour les mesures, comme illustré par l’affichage en fin de script.
# -*- coding: utf-8 -*-
#
from numpy import array, arange
#
dimension = 7
#
print("Définition d'un ensemble artificiel de champs physiques")
print("-------------------------------------------------------")
Ensemble = array( [i+arange(dimension) for i in range(7)] ).T
print("- Dimension de l'espace des champs physiques...........: %i"%dimension)
print("- Nombre de vecteurs de champs physiques...............: %i"%Ensemble.shape[1])
print("- Collection des champs physiques (un par colonne)")
print(Ensemble)
print()
#
print("Recherche des positions optimales de mesure")
print("-------------------------------------------")
from adao import adaoBuilder
case = adaoBuilder.New()
case.setAlgorithmParameters(
Algorithm = "MeasurementsOptimalPositioningTask",
Parameters = {
"EnsembleOfSnapshots":Ensemble,
"MaximumNumberOfLocations":3,
"ErrorNorm":"L2",
}
)
case.execute()
print("- Calcul ADAO effectué")
print()
#
print("Affichage des positions optimales de mesure")
print("-------------------------------------------")
op = case.get("OptimalPoints")[-1]
print("- Nombre de positions optimales de mesure..............: %i"%op.size)
print("- Positions optimales de mesure, numérotées par défaut.: %s"%op)
print()
Le résultat de son exécution est le suivant :
Définition d'un ensemble artificiel de champs physiques
-------------------------------------------------------
- Dimension de l'espace des champs physiques...........: 7
- Nombre de vecteurs de champs physiques...............: 7
- Collection des champs physiques (un par colonne)
[[ 0 1 2 3 4 5 6]
[ 1 2 3 4 5 6 7]
[ 2 3 4 5 6 7 8]
[ 3 4 5 6 7 8 9]
[ 4 5 6 7 8 9 10]
[ 5 6 7 8 9 10 11]
[ 6 7 8 9 10 11 12]]
Recherche des positions optimales de mesure
-------------------------------------------
- Calcul ADAO effectué
Affichage des positions optimales de mesure
-------------------------------------------
- Nombre de positions optimales de mesure..............: 2
- Positions optimales de mesure, numérotées par défaut.: [6 0]
15.3.5.2. Second exemple¶
Cet exemple décrit le même positionnement optimal de mesures, suivi d’une analyse de la représentation réduite et des erreurs obtenues lors de la recherche des positions optimales.
La partie initiale du script est identique au précédent, avec la même collection artificielle de champs physiques et la même analyse par ADAO. On ajoute ensuite la récupération de la base réduite et un exemple très simple de décomposition sur la base réduite, exacte dans ce cas simple, de l’un des champs physiques initialement fournis.
# -*- coding: utf-8 -*-
#
from numpy import array, arange
#
dimension = 7
#
print("Définition d'un ensemble artificiel de champs physiques")
print("-------------------------------------------------------")
Ensemble = array( [i+arange(dimension) for i in range(7)] ).T
print("- Dimension de l'espace des champs physiques...........: %i"%dimension)
print("- Nombre de vecteurs de champs physiques...............: %i"%Ensemble.shape[1])
print("- Collection des champs physiques (un par colonne)")
print(Ensemble)
print()
#
print("Recherche des positions optimales de mesure")
print("-------------------------------------------")
from adao import adaoBuilder
case = adaoBuilder.New()
case.setAlgorithmParameters(
Algorithm = "MeasurementsOptimalPositioningTask",
Parameters = {
"EnsembleOfSnapshots":Ensemble,
"MaximumNumberOfLocations":3,
"ErrorNorm":"L2",
"StoreSupplementaryCalculations":[
"ReducedBasis",
"Residus",
],
}
)
case.execute()
print("- Calcul ADAO effectué")
print()
#
print("Affichage des positions optimales de mesure")
print("-------------------------------------------")
op = case.get("OptimalPoints")[-1]
print("- Nombre de positions optimales de mesure..............: %i"%op.size)
print("- Positions optimales de mesure, numérotées par défaut.: %s"%op)
print()
#
print("Représentation réduite et informations d'erreurs")
print("------------------------------------------------")
rb = case.get("ReducedBasis")[-1]
print("- Nombre de vecteurs de la base réduite................: %i"%rb.shape[1])
print("- Vecteurs de la base réduite (un par colonne)\n")
print(rb)
rs = case.get("Residus")[-1]
print("- Résidus ordonnés d'erreur de reconstruction\n ",rs)
print()
a0, a1 = 7, -2.5
print("- Exemple élémentaire de reconstruction du second champ comme une")
print(" combinaison linéaire des deux vecteurs de base, qui peuvent être")
print(" multipliés par les coefficients respectifs %.1f et %.1f :"%(a0,a1))
print( a0*rb[:,0] + a1*rb[:,1])
print()
Le résultat de son exécution est le suivant :
Définition d'un ensemble artificiel de champs physiques
-------------------------------------------------------
- Dimension de l'espace des champs physiques...........: 7
- Nombre de vecteurs de champs physiques...............: 7
- Collection des champs physiques (un par colonne)
[[ 0 1 2 3 4 5 6]
[ 1 2 3 4 5 6 7]
[ 2 3 4 5 6 7 8]
[ 3 4 5 6 7 8 9]
[ 4 5 6 7 8 9 10]
[ 5 6 7 8 9 10 11]
[ 6 7 8 9 10 11 12]]
Recherche des positions optimales de mesure
-------------------------------------------
- Calcul ADAO effectué
Affichage des positions optimales de mesure
-------------------------------------------
- Nombre de positions optimales de mesure..............: 2
- Positions optimales de mesure, numérotées par défaut.: [6 0]
Représentation réduite et informations d'erreurs
------------------------------------------------
- Nombre de vecteurs de la base réduite................: 2
- Vecteurs de la base réduite (un par colonne)
[[ 0.5 1. ]
[ 0.58333333 0.83333333]
[ 0.66666667 0.66666667]
[ 0.75 0.5 ]
[ 0.83333333 0.33333333]
[ 0.91666667 0.16666667]
[ 1. -0. ]]
- Résidus ordonnés d'erreur de reconstruction
[2.43926218e+01 4.76969601e+00 2.51214793e-15]
- Exemple élémentaire de reconstruction du second champ comme une
combinaison linéaire des deux vecteurs de base, qui peuvent être
multipliés par les coefficients respectifs 7.0 et -2.5 :
[[1.]
[2.]
[3.]
[4.]
[5.]
[6.]
[7.]]
15.3.5.3. Positionnement optimal de mesures associé à une décomposition DEIM¶
Cet exemple plus complet décrit le positionnement optimal de mesures associé à
une décomposition réduite de type DEIM sur une fonction classique paramétrique
non-linéaire, telle que proposée dans la référence [Chaturantabut10]. Cette
fonction particulière a l’avantage notable de n’être dépendante que d’une
position 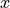 en 2D et d’un paramètre en 2D aussi. Elle permet
donc une illustration pédagogique pour représenter les points optimaux de
mesure.
en 2D et d’un paramètre en 2D aussi. Elle permet
donc une illustration pédagogique pour représenter les points optimaux de
mesure.
Cette fonction  dépend de la position
dépend de la position
![x=(x_1,x_2)\in\Omega=[0.1,0.9]^2](_images/math/08663eb1009c16f44190c7763192abc28b6508f3.png) dans le plan 2D, et du paramètre
dans le plan 2D, et du paramètre
![\mu=(\mu_1,\mu_2)\in\mathcal{D}=[-1,-0.01]^2](_images/math/ad456d635018eae21f8c1f0fb5c9f60d55be15be.png) de dimension 2 :
de dimension 2 :
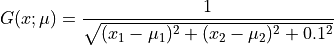
La fonction est représenté sur une grille spatiale régulière 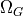 de taille 20x20 points. Elle est disponible dans les modèles de tests intégrés
pour ADAO sous le nom
de taille 20x20 points. Elle est disponible dans les modèles de tests intégrés
pour ADAO sous le nom TwoDimensionalInverseDistanceCS2010. On construit
donc ici tout d’abord un ensemble de simulations de pour différents
paramètres , puis on cherche les meilleurs positions de mesures pour
obtenir une représentation par interpolation DEIM des champs, en appliquant
l’algorithme de décomposition de type DEIM, et on en tire ensuite des
illustrations simples. On choisit de rechercher un nombre arbitraire
nbmeasures de 15 positions de mesures.
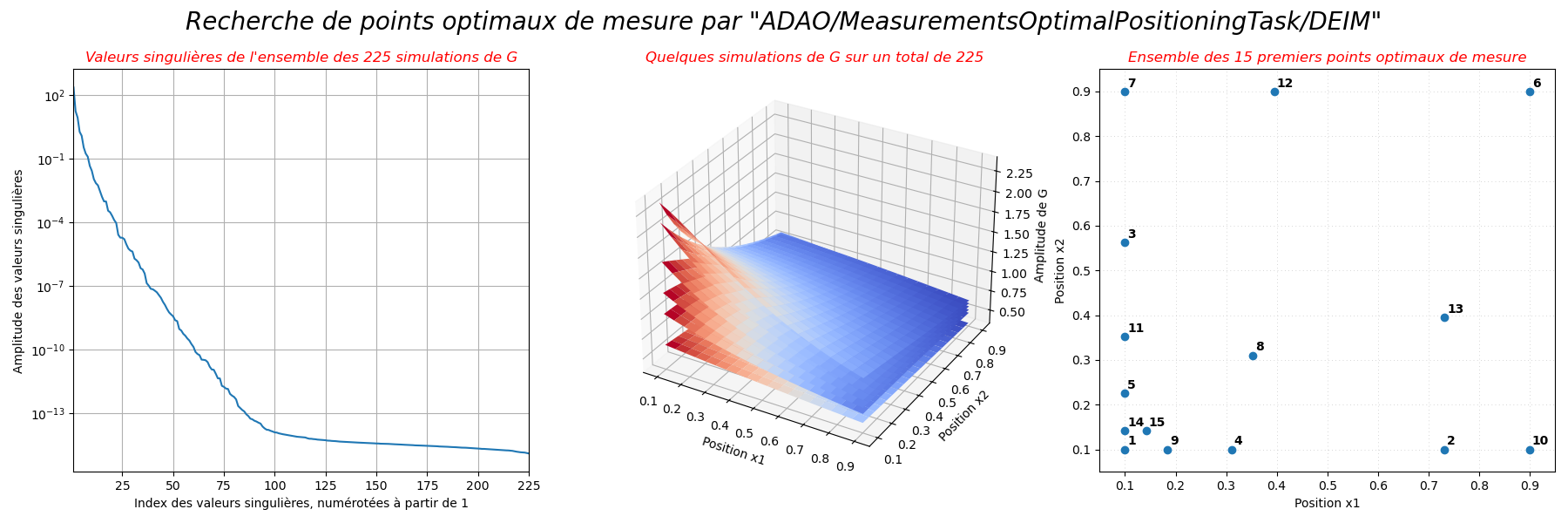
On observe ainsi que les valeurs singulières décroissent régulièrement jusqu’au
bruit numérique, indiquant qu’il faut environ une centaine d’éléments de base
pour complètement représenter l’information contenue dans l’ensemble des
simulations paramétriques de . Par ailleurs, les points de mesure
optimaux dans le domaine sont répartis de manière inhomogène,
privilégiant la zone spatiale proche du coin 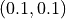 dans laquelle la
fonction varie le plus.
dans laquelle la
fonction varie le plus.
# -*- coding: utf-8 -*-
#
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(123456789)
#
dimension = 20
nbmeasures = 15
#
print("Définition d'un ensemble artificiel de champs physiques")
from Models.TwoDimensionalInverseDistanceCS2010 \
import TwoDimensionalInverseDistanceCS2010 as Equation
Eq = Equation(dimension, dimension)
print()
#
print("Recherche des positions optimales de mesure")
from adao import adaoBuilder
case = adaoBuilder.New()
case.setAlgorithmParameters(
Algorithm = "MeasurementsOptimalPositioningTask",
Parameters = {
"Variant":"DEIM",
"SampleAsnUplet":Eq.get_sample_of_mu(15, 15),
"MaximumNumberOfLocations":nbmeasures,
"ErrorNorm":"Linf",
"ErrorNormTolerance":0.,
"StoreSupplementaryCalculations":[
"SingularValues",
"OptimalPoints",
"EnsembleOfSimulations",
],
}
)
case.setBackground(Vector = [1,1] )
case.setObservationOperator(OneFunction = Eq.OneRealisation)
case.execute()
#
#-------------------------------------------------------------------------------
print()
print("Affichage graphique des résultats")
#
sp = case.get("EnsembleOfSimulations")[-1]
sv = case.get("SingularValues")[-1]
op = case.get("OptimalPoints")[-1]
#
x1, x2 = Eq.get_x()
x1, x2 = np.meshgrid(x1, x2)
posx1 = [x1.reshape((-1,))[ip] for ip in op]
posx2 = [x2.reshape((-1,))[ip] for ip in op]
Omega = Eq.get_bounds_on_space()
#
fig = plt.figure(figsize=(18, 6))
name = "Recherche de points optimaux de mesure par "
name += '"ADAO/MeasurementsOptimalPositioningTask/DEIM"'
fig.suptitle(name, fontsize=20, fontstyle="italic")
#
ax = fig.add_subplot(1, 3, 1)
name = "Valeurs singulières de l'ensemble des %i simulations de G"%sp.shape[1]
print(" -", name)
ax.set_title(name, fontstyle="italic", color="red")
ax.set_xlabel("Index des valeurs singulières, numérotées à partir de 1")
ax.set_ylabel("Amplitude des valeurs singulières")
ax.set_xlim(1, len(sv))
ax.set_yscale("log")
ax.grid(True)
ax.plot(range(1, 1 + len(sv)), sv)
#
ax = fig.add_subplot(1, 3, 2, projection = "3d")
name = "Quelques simulations de G sur un total de %i"%sp.shape[1]
print(" -", name)
ax.set_title(name, fontstyle="italic", color="red")
ax.set_xlabel("Position x1")
ax.set_ylabel("Position x2")
ax.set_zlabel("Amplitude de G")
for i in range(sp.shape[1]):
if i % 44 != 0: continue
Gfield = sp[:,i].reshape((dimension, dimension))
ax.plot_surface(x1, x2, Gfield, cmap="coolwarm")
#
ax = fig.add_subplot(1, 3, 3)
name = "Ensemble des %i premiers points optimaux de mesure"%nbmeasures
print(" -", name)
ax.set_title(name, fontstyle="italic", color="red")
ax.set_xlabel("Position x1")
ax.set_ylabel("Position x2")
ax.set_xlim(Omega[0][0] - 0.05, Omega[0][1] + 0.05)
ax.set_ylim(Omega[1][0] - 0.05, Omega[1][1] + 0.05)
ax.grid(True, which="both", linestyle=(0, (1, 5)), linewidth=0.5)
ax.plot(posx1, posx2, markersize=6, marker="o", linestyle="")
for i in range(len(posx1)):
ax.text(posx1[i] + 0.005, posx2[i] + 0.01, str(i + 1), fontweight="bold")
#
plt.tight_layout()
fig.savefig("simple_MeasurementsOptimalPositioningTask3.png")
plt.close()
Le résultat de son exécution est le suivant :
Définition d'un ensemble artificiel de champs physiques
Recherche des positions optimales de mesure
Affichage graphique des résultats
- Valeurs singulières de l'ensemble des 225 simulations de G
- Quelques simulations de G sur un total de 225
- Ensemble des 15 premiers points optimaux de mesure
Les graphiques illustrant le résultat de son exécution sont les suivants :