2. [DocT] Une brève introduction à l’Assimilation de Données et à l’Optimisation¶
L’assimilation de données est un cadre général bien établi pour le calcul de l’estimation optimale de l’état réel d’un système, au cours du temps si nécessaire. Il utilise les valeurs obtenues en combinant des observations et des modèles a priori, incluant de plus des informations sur leurs erreurs tout en respectant simultanément des contraintes. Cela tient donc compte des lois du comportement ou de la dynamique du système à travers les équations du modèle, et de la façon dont les mesures sont physiquement liées aux variables simulées.
En d’autres termes, l’assimilation de données est un moyen de fusionner les données mesurées d’un système, qui sont les observations, avec des connaissances physique et mathématique a priori du système, intégrées dans les modèles numériques. L’objectif est d’obtenir la meilleure estimation possible, appelée « analyse », de l’état réel du système et de ses propriétés stochastiques. On note que cet état réel (ou « état vrai ») ne peut être habituellement atteint, mais peut seulement être estimé. De plus, malgré le fait que les informations utilisées sont stochastiques par nature, l’assimilation de données fournit des techniques déterministes afin de réaliser l’estimation de manière très efficace.
Comme l’assimilation de données cherche l’estimation la meilleure possible, la démarche technique sous-jacente intègre toujours de l’optimisation afin de trouver cette estimation : des méthodes d’optimisation choisies sont toujours intégrées dans les algorithmes d’assimilation de données. Par ailleurs, les méthodes d’optimisation peuvent être vues dans ADAO comme un moyen d’étendre les applications d’assimilation de données. Elles seront présentées de cette façon dans la section pour Approfondir l’estimation d’état par des méthodes d’optimisation, mais elles sont beaucoup plus générales et peuvent être utilisées sans les concepts d’assimilation de données.
Deux types principaux d’applications existent en assimilation de données, qui sont couverts par le même formalisme : la reconstruction de champs (voir Reconstruction de champs ou interpolation de données) et l’identification de paramètres (voir Identification de paramètres, ajustement de modèles, ou calage). On parle aussi respectivement d’estimation d’état et d’estimation de paramètres, et l’on peut aussi estimer les deux de manière conjointe si nécessaire (voir Estimation conjointe d’états et de paramètres). Dans ADAO, certains algorithmes peuvent être utilisés soit en estimation d’état, soit en estimation de paramètres. Cela se fait simplement en changeant l’option requise « EstimationOf » dans les paramètres des algorithmes. Avant d’introduire la Description simple du cadre méthodologique de l’assimilation de données dans une prochaine section, on décrit brièvement ces deux types d’applications. A la fin de ce chapitre, quelques informations permettent d’aller plus loin pour Approfondir le cadre méthodologique de l’assimilation de données et Approfondir l’estimation d’état par des méthodes d’optimisation, ainsi que pour Approfondir l’assimilation de données pour la dynamique et avoir Un aperçu des méthodes de réduction et de l’optimisation réduite.
2.1. Reconstruction de champs ou interpolation de données¶
La reconstruction (ou l’interpolation) de champs consiste à trouver, à partir d’un nombre restreint de mesures réelles, le (ou les) champ(s) physique(s) qui est (sont) le(s) plus cohérent(s) avec ces mesures.
La cohérence est à comprendre en termes d’interpolation, c’est-à-dire que le champ que l’on cherche à reconstruire, en utilisant de l’assimilation de données sur les mesures, doit s’adapter au mieux aux mesures, tout en restant contraint par la simulation globale du champ. Le champ calculé est donc une estimation a priori du champ que l’on cherche à identifier. On parle aussi d’estimation d’état dans ce cas.
Si le système évolue dans le temps, la reconstruction du champ dans son ensemble doit être établie à chaque pas de temps, en tenant compte des informations sur une fenêtre temporelle. Le processus d’interpolation est plus compliqué dans ce cas car il est temporel, et plus seulement en termes de valeurs instantanées du champ.
Un exemple simple de reconstruction de champs provient de la météorologie, dans laquelle on recherche les valeurs de variables comme la température ou la pression en tout point du domaine spatial. On dispose de mesures instantanées de ces quantités en certains points, mais aussi d’un historique de ces mesures. De plus, ces variables sont contraintes par les équations d’évolution de l’atmosphère, qui indiquent par exemple que la pression en un point ne peut pas prendre une valeur quelconque indépendamment de la valeur au même point à un temps précédent. On doit donc faire la reconstruction d’un champ en tout point de l’espace, de manière « cohérente » avec les équations d’évolution et avec les mesures aux précédents pas de temps.
2.2. Identification de paramètres, ajustement de modèles, ou calage¶
L’identification (ou l’ajustement) de paramètres par assimilation de données est une forme de calage d’état qui utilise simultanément les mesures physiques et une estimation a priori des paramètres (appelée « l’ébauche ») d’état que l’on cherche à identifier, ainsi qu’une caractérisation de leurs erreurs. De ce point de vue, cette démarche utilise toutes les informations disponibles sur le système physique, avec des hypothèses restrictives mais réalistes sur les erreurs, pour trouver « l’estimation optimale » de l’état vrai. On peut noter, en termes d’optimisation, que l’ébauche réalise la « régularisation », au sens mathématique de Tikhonov [Tikhonov77] [WikipediaTI], du problème principal d’identification de paramètres. On peut aussi désigner cette démarche comme une résolution de type « problème inverse ».
En pratique, les deux écarts (ou incréments) observés « calculs-mesures » et « calculs-ébauche » sont combinés pour construire la correction de calage des paramètres ou des conditions initiales. L’ajout de ces deux incréments requiert une pondération relative, qui est choisie pour refléter la confiance que l’on donne à chaque information utilisée. Cette confiance est représentée par la covariance des erreurs sur l’ébauche et sur les observations. Ainsi l’aspect stochastique des informations est essentiel pour construire une fonction d’erreur pour le calage.
Un exemple simple d’identification de paramètres provient de tout type de simulation physique impliquant un modèle paramétré. Par exemple, une simulation de mécanique statique d’une poutre contrainte par des forces est décrite par les paramètres de la poutre, comme un coefficient de Young, ou par l’intensité des forces appliquées. Le problème d’estimation de paramètres consiste à chercher par exemple la bonne valeur du coefficient de Young de telle manière à ce que la simulation de la poutre corresponde aux mesures, en y incluant la connaissance des erreurs.
Toutes les grandeurs représentant la description de la physique dans un modèle sont susceptibles d’être calibrées dans une démarche d’assimilation de données, que ce soient des paramètres de modèles, des conditions initiales ou des conditions aux limites. Leur prise en compte simultanée est largement facilitée par la démarche d’assimilation de données, permettant de traiter objectivement un ensemble hétérogène d’informations à disposition.
2.3. Estimation conjointe d’états et de paramètres¶
Il parfois nécessaire, en considérant les deux types d’applications précédentes, d’avoir besoin d’estimer en même temps des états (champs) et des paramètres caractérisant un phénomène physique. On parle alors d’estimation conjointe d’états et de paramètres.
Sans rentrer ici dans les méthodes avancées pour résoudre ce problème, on peut mentionner la démarche conceptuellement très simple consistant à considérer le vecteur des états à interpoler comme augmenté par le vecteur des paramètres à caler. On note que l’on est globalement en estimation d’état ou reconstruction de champs, et que dans le cas temporel de l’identification de paramètres, l’évolution des paramètres à estimer est simplement l’identité. Les algorithmes d’assimilation ou d’optimisation peuvent ensuite être appliqués au vecteur augmenté. Valable dans le cas de non-linéarités modérées dans la simulation, cette méthode simple étend l’espace d’optimisation, et conduit donc à des problèmes plus gros, mais il est souvent possible de réduire la représentation pour revenir à des cas numériquement calculables. Sans exhaustivité, l’optimisation à variables séparées, le filtrage de rang réduit, ou le traitement spécifique des matrices de covariances, sont des techniques courantes pour éviter ce problème de dimension. Dans le cas temporel, on verra ci-après des indications pour une Estimation conjointe d’état et de paramètres en dynamique.
Pour aller plus loin, on se référera aux méthodes mathématiques d’optimisation et d’augmentation développées dans de nombreux ouvrages ou articles spécialisés, trouvant leur origine par exemple dans [Lions68], [Jazwinski70] ou [Dautray85]. En particulier dans le cas de non-linéarités plus marquées lors de la simulation numérique des états, il convient de traiter de manière plus complète mais aussi plus complexe le problème d’estimation conjointe d’états et de paramètres.
2.4. Description simple du cadre méthodologique de l’assimilation de données¶
On peut décrire ces démarches de manière simple. Par défaut, toutes les variables sont des vecteurs, puisqu’il y a plusieurs paramètres à ajuster, ou un champ discrétisé à reconstruire.
Selon les notations standards en assimilation de données, on note
 les paramètres optimaux qui doivent être déterminés par
calage,
les paramètres optimaux qui doivent être déterminés par
calage,  les observations (ou les mesures expérimentales)
auxquelles on doit comparer les sorties de simulation,
les observations (ou les mesures expérimentales)
auxquelles on doit comparer les sorties de simulation,  l’ébauche (valeurs a priori, ou valeurs de régularisation) des paramètres
cherchés,
l’ébauche (valeurs a priori, ou valeurs de régularisation) des paramètres
cherchés,  les paramètres inconnus idéaux qui donneraient
exactement les observations (en supposant que toutes les erreurs soient nulles
et que le modèle soit exact) en sortie.
les paramètres inconnus idéaux qui donneraient
exactement les observations (en supposant que toutes les erreurs soient nulles
et que le modèle soit exact) en sortie.
Dans le cas le plus simple, qui est statique, les étapes de simulation et
d’observation peuvent être combinées en un unique opérateur d’observation noté
 (linéaire ou non-linéaire). Il transforme formellement les
paramètres
(linéaire ou non-linéaire). Il transforme formellement les
paramètres  en entrée en résultats
en entrée en résultats  , qui
peuvent être directement comparés aux observations :
, qui
peuvent être directement comparés aux observations :

De plus, on utilise l’opérateur linéarisé (ou tangent)  pour
représenter l’effet de l’opérateur complet autour d’un
point de linéarisation (et on omettra usuellement ensuite de mentionner
, même si l’on peut le conserver, pour ne mentionner que
). En réalité, on a déjà indiqué que la nature stochastique
des variables est essentielle, provenant du fait que le modèle, l’ébauche et
les observations sont tous incorrects. On introduit donc des erreurs
d’observations additives, sous la forme d’un vecteur aléatoire
pour
représenter l’effet de l’opérateur complet autour d’un
point de linéarisation (et on omettra usuellement ensuite de mentionner
, même si l’on peut le conserver, pour ne mentionner que
). En réalité, on a déjà indiqué que la nature stochastique
des variables est essentielle, provenant du fait que le modèle, l’ébauche et
les observations sont tous incorrects. On introduit donc des erreurs
d’observations additives, sous la forme d’un vecteur aléatoire
 tel que :
tel que :

Les erreurs représentées ici ne sont pas uniquement celles des observations, ce
sont aussi celles de la simulation. On peut toujours considérer que ces erreurs
sont de moyenne nulle. En notant ![E[.]](_images/math/c361a91e6d41dfa5314e3fbd8f60759a63f36659.png) l’espérance mathématique
classique, on peut alors définir une matrice
l’espérance mathématique
classique, on peut alors définir une matrice  des covariances
d’erreurs d’observation par l’expression :
des covariances
d’erreurs d’observation par l’expression :
![\mathbf{R} = E[\mathbf{\epsilon}^o.{\mathbf{\epsilon}^o}^T]](_images/math/484125fedec951416b6bf153078fb532cb6056d9.png)
L’ébauche peut être écrite formellement comme une fonction de la valeur vraie,
en introduisant le vecteur d’erreurs  tel que :
tel que :

Les erreurs d’ébauche sont aussi supposées de
moyenne nulle, de la même manière que pour les observations. On définit la
matrice  des covariances d’erreurs d’ébauche par :
des covariances d’erreurs d’ébauche par :
![\mathbf{B} = E[\mathbf{\epsilon}^b.{\mathbf{\epsilon}^b}^T]](_images/math/f49ea4bb8b9e39eaa79a1b9bbb8b4c9e77c3762c.png)
L’estimation optimale des paramètres vrais , étant donné
l’ébauche et les observations , est
ainsi appelée une « analyse », notée , et provient de la
minimisation d’une fonction d’erreur, explicite en assimilation variationnelle,
ou d’une correction de filtrage en assimilation par filtrage.
En assimilation variationnelle, dans un cas statique, on cherche
classiquement à minimiser la fonction  suivante :
suivante :

est classiquement désignée comme la fonctionnelle « 3D-Var » en
assimilation de données (voir par exemple [Talagrand97]) ou comme la
fonctionnelle de régularisation de Tikhonov généralisée en optimisation (voir
par exemple [WikipediaTI]). Comme les matrices de covariance
et sont proportionnelles aux variances
d’erreurs, leur présence dans les deux termes de la fonctionnelle
permet effectivement de pondérer les termes d’écarts par la confiance dans les
erreurs d’ébauche ou d’observations. Le vecteur des
paramètres réalisant le minimum de cette fonction constitue ainsi l’analyse
. C’est à ce niveau que l’on doit utiliser toute la
panoplie des méthodes de minimisation de fonctions connues par ailleurs en
optimisation (voir aussi la section Approfondir l’estimation d’état par des méthodes d’optimisation). Selon
la taille du vecteur des paramètres à identifier, et la
disponibilité du gradient ou de la hessienne de , il est judicieux
d’adapter la méthode d’optimisation choisie (gradient, Newton,
quasi-Newton…).
En assimilation par filtrage, dans ce cas simple usuellement dénommé
« BLUE » (pour « Best Linear Unbiased Estimator »), l’analyse
est donnée comme une correction de l’ébauche
par un terme proportionnel à la différence entre les
observations et les calculs  :
:

où  est la matrice de gain de Kalman, qui s’exprime à l’aide
des matrices de covariance sous la forme suivante :
est la matrice de gain de Kalman, qui s’exprime à l’aide
des matrices de covariance sous la forme suivante :

L’avantage du filtrage est le calcul explicite du gain, pour produire ensuite la matrice a posteriori de covariance d’analyse.
Dans ce cas statique simple, on peut montrer, sous une hypothèse de
distributions gaussiennes d’erreurs (très peu restrictive en pratique) et de
linéarité de , que les deux approches variationnelle et
de filtrage donnent la même solution.
On indique que ces méthodes de « 3D-Var » et de « BLUE » peuvent être étendues à des problèmes dynamiques ou temporels, sous les noms respectifs de « 4D-Var » et de « Filtre de Kalman (KF) » et leurs dérivés. Elles doivent alors prendre en compte un opérateur d’évolution pour établir aux bons pas de temps une analyse de l’écart entre les observations et les simulations et pour avoir, à chaque instant, la propagation de l’ébauche à travers le modèle d’évolution. On se reportera à la section suivante pour Approfondir l’assimilation de données pour la dynamique. De la même manière, ces méthodes peuvent aussi être utilisées dans le cas d’opérateurs d’observation ou d’évolution non linéaires. Un grand nombre de variantes ont été développées pour accroître la qualité numérique des méthodes ou pour prendre en compte des contraintes informatiques comme la taille ou la durée des calculs.
2.5. Une vue schématique des approches d’Assimilation de Données et d’Optimisation¶
Pour aider le lecteur à se faire un idée des approches utilisables avec ADAO en Assimilation de Données et en Optimisation, on propose ici un schéma simplifié décrivant une classification arbitraire des méthodes. Il est partiellement et librement inspiré de [Asch16] (Figure 1.5).
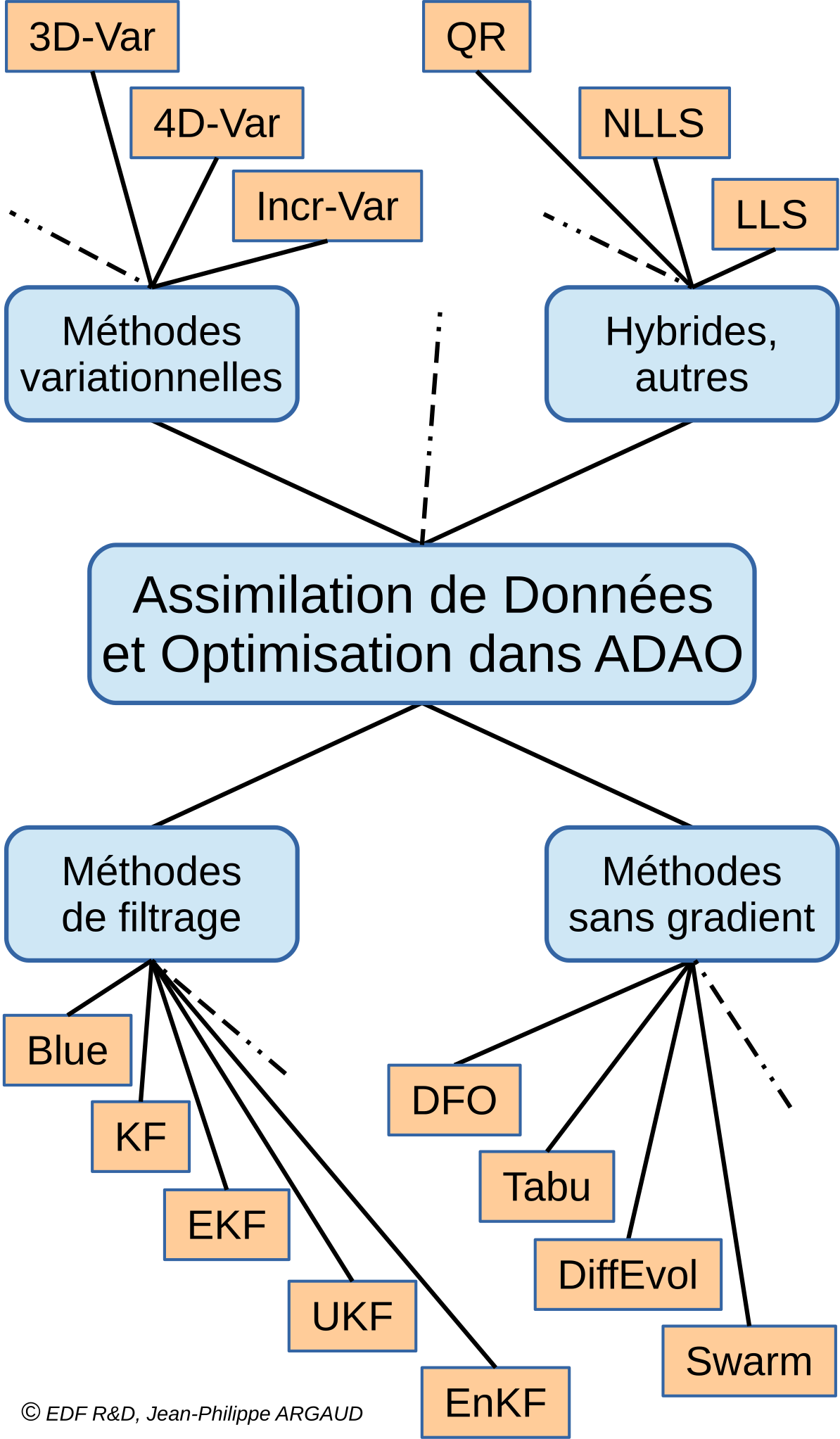
Une classification simplifiée de méthodes utilisables avec ADAO en Assimilation de Données et en Optimisation (les acronymes et les liens descriptifs internes sont énumérés ci-dessous)
Il est volontairement simple pour rester lisible, les lignes tiretées montrant certaines des simplifications ou extensions. Ce schéma omet par exemple de citer spécifiquement les méthodes avec réductions (dont il est donné ci-après Un aperçu des méthodes de réduction et de l’optimisation réduite), dont une partie sont des variantes de méthodes de base indiquées ici, ou de citer les extensions les plus détaillées. Il omet de même les méthodes de tests disponibles dans ADAO et utiles pour la mise en étude.
Chaque méthode citée dans ce schéma fait l’objet d’une partie descriptive spécifique dans le chapitre des [DocR] Cas d’assimilation de données ou d’optimisation. Les acronymes cités dans le schéma ont la signification indiquée dans les pointeurs associés :
3D-Var : Algorithme de calcul « 3DVAR »,
4D-Var : Algorithme de calcul « 4DVAR »,
Blue : Algorithme de calcul « Blue »,
DiffEvol : Algorithme de calcul « DifferentialEvolution »,
Incr-Var : Incremental version Variational optimisation,
2.6. Un aperçu des méthodes de réduction et de l’optimisation réduite¶
Les démarches d’assimilation de données et d’optimisation impliquent toujours une certaine réitération d’une simulation numérique unitaire représentant la physique que l’on veut traiter. Pour traiter au mieux cette physique, cette simulation numérique unitaire est souvent de taille importante voire imposante, et conduit à un coût calcul extrêmement important dès lors qu’il est répété. La simulation physique complète est souvent appelée « simulation haute fidélité » (ou « high fidelity simulation » ou « full scale simulation »).
Pour éviter cette difficulté pratique, différentes stratégies de réduction du coût du calcul d’optimisation existent, et certaines permettent également de contrôler au mieux l’erreur numérique impliquée par cette réduction. Ces stratégies sont intégrées de manière transparente à certaines des méthodes d’ADAO ou font l’objet d’algorithmes particuliers.
Pour établir une telle démarche, on cherche à réduire au moins l’un des ingrédients qui composent le problème d’assimilation de données ou d’optimisation. On peut ainsi classer les méthodes de réduction selon l’ingrédient sur lequel elles opèrent, en sachant que certaines méthodes portent sur plusieurs d’entre eux. On indique ici une classification grossière, que le lecteur peut compléter par la lecture d’ouvrages ou d’articles généraux en mathématiques ou spécialisés pour sa physique.
- Réduction des algorithmes d’assimilation de données ou d’optimisation :
les algorithmes d’optimisation eux-mêmes peuvent engendrer des coûts de calculs importants pour traiter les informations numériques. Diverses méthodes permettent de réduire leur coût algorithmique, par exemple en travaillant dans l’espace réduit le plus adéquat pour l’optimisation, ou en utilisant des techniques d’optimisation multi-niveaux. ADAO dispose de telles techniques qui sont incluses dans les variantes d’algorithmes classiques, conduisant à des résolutions exactes ou approximées mais numériquement plus efficaces. Par défaut, les options algorithmiques choisies par défaut dans ADAO sont toujours les plus performantes lorsqu’elles n’impactent pas la qualité de l’optimisation.
- Réduction de la représentation des covariances :
dans les algorithmes d’assimilation de données, ce sont les covariances qui sont les grandeurs les plus coûteuses à manipuler ou à stocker, devenant souvent les quantités limitantes du point de vue du coût de calcul. De nombreuses méthodes cherchent donc à utiliser une représentation réduite de ces matrices (conduisant parfois mais pas obligatoirement à réduire aussi la dimension l’espace d’optimisation). On utilise classiquement des techniques de factorisation, de décomposition (spectrale, Fourier, ondelettes…) ou d’estimation d’ensemble (EOF…), ou des combinaisons, pour réduire la charge numérique de ces covariances dans les calculs. ADAO utilise certaines de ces techniques, en combinaison avec des techniques de calcul creux (« sparse »), pour rendre plus efficace la manipulation des matrices de covariance.
- Réduction du modèle physique :
la manière la plus simple de réduire le coût du calcul unitaire consiste à réduire le modèle de simulation lui-même, en le représentant de manière numériquement plus économique. De nombreuses méthodes permettent cette réduction de modèles en assurant un contrôle plus ou moins strict de l’erreur d’approximation engendrée par la réduction. L’usage de modèles simplifiés de la physique permet une réduction mais sans toujours produire un contrôle d’erreur. Au contraire, toutes les méthodes de décomposition (Fourier, ondelettes, SVD, POD, PCA, Kahrunen-Loeve, RBM, EIM, etc.) visent ainsi une réduction de l’espace de représentation avec un contrôle d’erreur explicite. Très fréquemment utilisées, elles doivent néanmoins être complétées par une analyse fine de l’interaction avec l’algorithme d’optimisation dans lequel le calcul réduit est inséré, pour éviter des instabilités, incohérences ou inconsistances notoirement préjudiciables. ADAO supporte complètement l’usage de ce type de méthode de réduction, même s’il est souvent nécessaire d’établir cette réduction indépendante générique préalablement à l’optimisation.
- Réduction de l’espace d’assimilation de données ou d’optimisation :
la taille de l’espace d’optimisation dépend grandement du type de problème traité (estimation d’états ou de paramètres) mais aussi du nombre d’observations dont on dispose pour conduire l’assimilation de données. Il est donc parfois possible de conduire l’optimisation dans l’espace le plus petit par une adaptation de la formulation interne des algorithmes d’optimisation. Lorsque c’est possible et judicieux, ADAO intègre ce genre de formulation réduite pour améliorer la performance numérique sans amoindrir la qualité de l’optimisation.
- Combinaison de plusieurs réductions :
de nombreux algorithmes avancés cherchent à combiner simultanément plusieurs techniques de réduction. Néanmoins, il est difficile de disposer à la fois de méthodes génériques et robustes, et d’utiliser en même temps de plusieurs techniques très performantes de réduction. ADAO intègre certaines méthodes parmi les plus robustes, mais cet aspect fait toujours largement l’objet de recherches et d’évolutions.
On peut terminer ce rapide tour d’horizon des méthodes de réduction en soulignant que leur usage est omniprésent dans les applications réelles et dans les outils numériques, et qu’ADAO permet d’utiliser des méthodes éprouvées sans même le savoir.
2.7. Approfondir le cadre méthodologique de l’assimilation de données¶
Pour obtenir de plus amples informations sur les techniques d’assimilation de données, le lecteur peut consulter les documents introductifs comme [Talagrand97] ou [Argaud09], des supports de formations ou de cours comme [Bouttier99] et [Bocquet04] (ainsi que d’autres documents issus des applications des géosciences), ou des documents généraux comme [Talagrand97], [Tarantola87], [Asch16], [Kalnay03], [Ide97], [Tikhonov77] et [WikipediaDA]. De manière plus mathématique, on pourra aussi consulter [Lions68], [Jazwinski70].
On note que l’assimilation de données n’est pas limitée à la météorologie ou aux géo-sciences, mais est largement utilisée dans d’autres domaines scientifiques. Il y a de nombreux champs d’applications scientifiques et technologiques dans lesquels l’utilisation efficace des données observées, mais incomplètes, est cruciale.
Certains aspects de l’assimilation de données sont aussi connus sous d’autres noms. Sans être exhaustif, on peut mentionner les noms de calage ou de recalage, de calibration, d’estimation d’état, d’estimation de paramètres, d’ajustement de paramètres, de problèmes inverses ou d’inversion, d’estimation bayésienne, d’interpolation de champs ou d’interpolation optimale, d’optimisation variationnelle, d’optimisation quadratique, de régularisation mathématique, de méta-heuristiques d’optimisation, de réduction de modèles, de lissage de données, de pilotage des modèles par les données (« data-driven »), d’apprentissage de modèles et de données (Machine Learning et Intelligence Artificielle), etc. Ces termes peuvent être utilisés dans les recherches bibliographiques.
2.8. Approfondir l’estimation d’état par des méthodes d’optimisation¶
Comme vu précédemment, dans un cas de simulation statique, l’assimilation
variationnelle de données nécessite de minimiser la fonction objectif :
qui est dénommée la fonctionnelle du « 3D-Var ». Elle peut être vue comme la
forme étendue d’une minimisation moindres carrés, obtenue en ajoutant un terme
de régularisation utilisant  , et en pondérant les
différences par les deux matrices de covariances et
. La minimisation de la fonctionnelle conduit à la
meilleure estimation de l’état . Pour obtenir plus
d’informations sur ces notions, on se reportera aux ouvrages généraux de
référence comme [Tarantola87].
, et en pondérant les
différences par les deux matrices de covariances et
. La minimisation de la fonctionnelle conduit à la
meilleure estimation de l’état . Pour obtenir plus
d’informations sur ces notions, on se reportera aux ouvrages généraux de
référence comme [Tarantola87].
Les possibilités d’extension de cette estimation d’état, en utilisant de manière plus explicite des méthodes d’optimisation et leurs propriétés, peuvent être imaginées de deux manières.
En premier lieu, les méthodes classiques d’optimisation impliquent l’usage de
méthodes de minimisation variées souvent basées sur un gradient. Elles sont
extrêmement efficaces pour rechercher un minimum local isolé. Mais elles
nécessitent que la fonctionnelle soit suffisamment régulière et
différentiable, et elles ne sont pas en mesure de saisir des propriétés
globales du problème de minimisation, comme par exemple : minimum global,
ensemble de solutions équivalentes dues à une sur-paramétrisation, multiples
minima locaux, etc. Une démarche pour étendre les possibilités d’estimation
consiste donc à utiliser l’ensemble des méthodes d’optimisation existantes,
permettant la minimisation globale, diverses propriétés de robustesse de la
recherche, etc. Il existe de nombreuses méthodes de minimisation, comme les
méthodes stochastiques, évolutionnaires, les heuristiques et méta-heuristiques
pour les problèmes à valeurs réelles, etc. Elles peuvent traiter des
fonctionnelles en partie irrégulières ou bruitées, peuvent
caractériser des minima locaux, etc. Les principaux désavantages de ces
méthodes sont un coût numérique souvent bien supérieur pour trouver les
estimations d’états, et fréquemment aucune garantie de convergence en temps
fini. Ici, on ne mentionne que quelques méthodes disponibles dans ADAO :
Optimisation sans dérivées (Derivative Free Optimization ou DFO) (voir Algorithme de calcul « DerivativeFreeOptimization »),
Optimisation par essaim de particules (Particle Swarm Optimization ou PSO) (voir Algorithme de calcul « ParticleSwarmOptimization »),
Évolution différentielle (Differential Evolution ou DE) (voir Algorithme de calcul « DifferentialEvolution »),
Régression de quantile (Quantile Regression ou QR) (voir Algorithme de calcul « QuantileRegression »).
En second lieu, les méthodes d’optimisation cherchent usuellement à minimiser des mesures quadratiques d’erreurs, car les propriétés naturelles de ces fonctions objectifs sont bien adaptées à l’optimisation classique par gradient. Mais d’autres mesures d’erreurs peuvent être mieux adaptées aux problèmes de simulation de la physique réelle. Ainsi, une autre manière d’étendre les possibilités d’estimation consiste à utiliser d’autres mesures d’erreurs à réduire. Par exemple, on peut citer une erreur en valeur absolue, une erreur maximale, etc. On donne précisément ci-dessous les cas les plus classiques de mesures d’erreurs, en indiquant leur identifiant dans ADAO pour la sélection éventuelle d’un critère de qualité :
la fonction objectif pour la mesure d’erreur par moindres carrés pondérés et augmentés (qui est la fonctionnelle de base par défaut de tous les algorithmes en assimilation de données, souvent nommée la fonctionnelle du « 3D-Var », et qui est connue dans les critères de qualité pour ADAO sous les noms de « AugmentedWeightedLeastSquares », « AWLS » ou « DA ») est :
la fonction objectif pour la mesure d’erreur par moindres carrés pondérés (qui est le carré de la norme pondérée
 de l’innovation, avec un coefficient
de l’innovation, avec un coefficient  pour être homogène à la précédente, et qui est connue dans les critères de qualité pour ADAO sous les noms de « WeightedLeastSquares » ou « WLS ») est :
pour être homogène à la précédente, et qui est connue dans les critères de qualité pour ADAO sous les noms de « WeightedLeastSquares » ou « WLS ») est :
la fonction objectif pour la mesure d’erreur par moindres carrés (qui est le carré de la norme
de l’innovation, avec un coefficient pour être homogène aux précédentes, et qui est connue dans les critères de qualité pour ADAO sous les noms de « LeastSquares », « LS » ou « L2 ») est :
la fonction objectif pour la mesure d’erreur en valeur absolue (qui est la norme
 de l’innovation, et qui est connue dans les critères de qualité pour ADAO sous les noms de « AbsoluteValue » ou « L1 ») est :
de l’innovation, et qui est connue dans les critères de qualité pour ADAO sous les noms de « AbsoluteValue » ou « L1 ») est :
la fonction objectif pour la mesure d’erreur maximale (qui est la norme
 de l’innovation, et qui est connue dans les critères de qualité pour ADAO sous les noms de « MaximumError », « ME » ou « Linf ») est :
de l’innovation, et qui est connue dans les critères de qualité pour ADAO sous les noms de « MaximumError », « ME » ou « Linf ») est :
Ces mesures d’erreurs peuvent ne pas être différentiables comme pour les deux dernières, mais certaines méthodes d’optimisation peuvent quand même les traiter : heuristiques et méta-heuristiques pour les problèmes à valeurs réelles, etc. Comme précédemment, les principaux désavantages de ces méthodes sont un coût numérique souvent bien supérieur pour trouver les estimations d’états, et pas de garantie de convergence en temps fini. Ici encore, on ne mentionne que quelques méthodes qui sont disponibles dans ADAO :
Optimisation sans dérivées (Derivative Free Optimization ou DFO) (voir Algorithme de calcul « DerivativeFreeOptimization »),
Optimisation par essaim de particules (Particle Swarm Optimization ou PSO) (voir Algorithme de calcul « ParticleSwarmOptimization »),
Évolution différentielle (Differential Evolution ou DE) (voir Algorithme de calcul « DifferentialEvolution »).
Le lecteur intéressé par le sujet de l’optimisation pourra utilement commencer sa recherche grâce au point d’entrée [WikipediaMO].
2.9. Approfondir l’assimilation de données pour la dynamique¶
On peut analyser un système en évolution temporelle (dynamique) à l’aide de l’assimilation de données, pour tenir compte explicitement de l’écoulement du temps dans l’estimation d’état ou de paramètres. On introduit ici brièvement la problématique, et certains outils théoriques ou pratiques, pour faciliter le traitement utilisateur de telles situations. On indique néanmoins que la variété des problématiques physiques et utilisateur est grande, et qu’il est donc recommandé d’adapter le traitement aux contraintes, qu’elles soient physiques, numériques ou informatiques.
2.9.1. Forme générale de systèmes dynamiques¶
Les systèmes en évolution temporelle peuvent être étudiés ou représentés à l’aide de systèmes dynamiques. Dans ce cas, il est aisé de concevoir l’analyse de leur comportement à l’aide de l’assimilation de données (c’est même dans ce cas précis que la démarche d’assimilation de données a initialement été largement développée).
On formalise de manière simple le cadre de simulation numérique. Un système
dynamique simple sur l’état peut être décrit en temps
continu sous la forme :

où est le vecteur d’état inconnu,  est un
vecteur de contrôle externe connu, et
est un
vecteur de contrôle externe connu, et  l’opérateur
(éventuellement non linéaire) de la dynamique du système. C’est une Équation
Différentielle Ordinaire (EDO, ou ODE en anglais), du premier ordre, sur
l’état. En temps discret, ce système dynamique peut être écrit sous la forme
suivante :
l’opérateur
(éventuellement non linéaire) de la dynamique du système. C’est une Équation
Différentielle Ordinaire (EDO, ou ODE en anglais), du premier ordre, sur
l’état. En temps discret, ce système dynamique peut être écrit sous la forme
suivante :

pour une indexation  des temps discrets avec
des temps discrets avec  .
.
 est l’opérateur d’évolution discret, issu symboliquement de
par le schéma de discrétisation. Usuellement, on omet la
notation du temps dans l’opérateur d’évolution . L’approximation de
l’opérateur par introduit (ou ajoute, si elle
existe déjà) une erreur de modèle
est l’opérateur d’évolution discret, issu symboliquement de
par le schéma de discrétisation. Usuellement, on omet la
notation du temps dans l’opérateur d’évolution . L’approximation de
l’opérateur par introduit (ou ajoute, si elle
existe déjà) une erreur de modèle  .
.
On peut alors caractériser deux types d’estimation en dynamique, que l’on
décrit ci-après sur le système dynamique en temps discret : Estimation d’état
en dynamique et Estimation de paramètres en dynamique. Combinés, les deux
types peuvent permettre de faire une Estimation conjointe d’état et de
paramètres en dynamique. Dans ADAO, nombre d’algorithmes peuvent être
utilisés soit en estimation d’état, soit en estimation de paramètres. Cela se
fait simplement en modifiant l’option requise « EstimationOf » dans les
paramètres des algorithmes, qui change uniquement la manière dont le contrôle
est appliqué dans le cas où il n’est explicitement pas
inclus dans .
2.9.2. Estimation d’état en dynamique¶
L’estimation d’état peut être conduite par assimilation de données sur la version en temps discret du système dynamique, écrit sous la forme suivante :


où est l’état à estimer du système,  et
et  sont respectivement l’état calculé (non observé) et
mesuré (observé) du système, et
sont respectivement l’état calculé (non observé) et
mesuré (observé) du système, et  sont respectivement les
opérateurs d’évolution incrémentale et d’observation,
sont respectivement les
opérateurs d’évolution incrémentale et d’observation,
 et
et  sont respectivement
les bruits ou erreurs d’évolution et d’observation, et
sont respectivement
les bruits ou erreurs d’évolution et d’observation, et  est un contrôle externe connu. Les deux opérateurs et sont
directement utilisables en assimilation de données avec ADAO.
est un contrôle externe connu. Les deux opérateurs et sont
directement utilisables en assimilation de données avec ADAO.
2.9.3. Estimation de paramètres en dynamique¶
L’estimation de paramètres s’écrit un peu différemment pour être conduite par
assimilation de données. Les paramètres à estimer sont dénotés
 . Toujours sur la version en temps discret du système
dynamique, on recherche une correspondance
. Toujours sur la version en temps discret du système
dynamique, on recherche une correspondance  (« mapping ») non-linéaire,
paramétrée par , entre des entrées et
des mesures à chaque pas , l’erreur à
contrôler en fonction des paramètres étant
(« mapping ») non-linéaire,
paramétrée par , entre des entrées et
des mesures à chaque pas , l’erreur à
contrôler en fonction des paramètres étant
 . On peut procéder par
optimisation sur cette erreur, avec régularisation, ou par filtrage en écrivant
le problème représenté en estimation d’état :
. On peut procéder par
optimisation sur cette erreur, avec régularisation, ou par filtrage en écrivant
le problème représenté en estimation d’état :


où, cette fois, le choix des modèles d’erreurs d’évolution et d’observation
et conditionne la
performance de la convergence et du suivi des observations (alors que les
représentations d’erreurs proviennent du comportement de la physique dans le
cas de l’estimation d’état). L’estimation des paramètres se
fait par utilisation de paires  d’entrées et de sorties correspondantes. De plus, les fonctionnelles d’écart
sont posées sur la différence entre l’estimation en entrée et l’estimation en
sortie.
d’entrées et de sorties correspondantes. De plus, les fonctionnelles d’écart
sont posées sur la différence entre l’estimation en entrée et l’estimation en
sortie.
Dans ce cas de l’estimation de paramètres, pour appliquer les méthodes
d’assimilation de données, on impose donc l’hypothèse que l’opérateur
d’évolution est l’identité (Remarque : il n’est donc pas utilisé, mais doit
être déclaré dans ADAO, sous la forme par exemple d’une matrice à diagonale
unité), et l’opérateur d’observation est .
2.9.4. Estimation conjointe d’état et de paramètres en dynamique¶
Un cas spécial concerne l’estimation conjointe d’état et de paramètres utilisés
dans un système dynamique. On cherche à estimer conjointement l’état
(qui dépend du temps) et les paramètres
(qui ici ne dépendent pas du temps). Il existe plusieurs manières de traiter ce
problème, mais la plus générale consiste à utiliser comme ci-dessous un vecteur
d’état augmenté par les paramètres, et à étendre les opérateurs en conséquence.
Pour cela, en utilisant les notations des deux sous-sections précédentes, on
définit la variable auxiliaire  telle que :
telle que :
![\mathbf{w} = \left[
\begin{array}{c}
\mathbf{x} \\
\mathbf{a}
\end{array}
\right]
= \left[
\begin{array}{c}
\mathbf{w}_{|x} \\
\mathbf{w}_{|a}
\end{array}
\right]](_images/math/533dc55331d0e9945a7a957fc88746de3cfd4acc.png)
et les opérateurs d’évolution  et d’observation
et d’observation
 associés au problème augmenté :
associés au problème augmenté :
![\tilde{M}(\mathbf{w},\mathbf{u}) = \left[
\begin{array}{c}
M(\mathbf{w}_{|x},\mathbf{u}) \\
\mathbf{w}_{|a}
\end{array}
\right]
= \left[
\begin{array}{c}
M(\mathbf{x},\mathbf{u}) \\
\mathbf{a}
\end{array}
\right]](_images/math/075118b6063de6264f5d1408a70f5cc3e882d272.png)
![\tilde{H}(\mathbf{w}) = \left[
\begin{array}{c}
H(\mathbf{w}_{|x}) \\
G(\mathbf{w}_{|x},\mathbf{w}_{|a})
\end{array}
\right]
= \left[
\begin{array}{c}
H(\mathbf{x}) \\
G(\mathbf{x},\mathbf{a})
\end{array}
\right]](_images/math/5a7bf235478c635e770dec53bab5e5dbbae3039e.png)
Avec ces notations, en étendant les variables de bruit
 et
et  de manière adéquate, le
problème d’estimation conjointe en temps discret d’état et
de paramètres , à travers la variable conjointe
, s’écrit alors :
de manière adéquate, le
problème d’estimation conjointe en temps discret d’état et
de paramètres , à travers la variable conjointe
, s’écrit alors :


avec ![\mathbf{w}_{n}=[\mathbf{x}_n~~\mathbf{a}_n]^T](_images/math/ce2db87e449a02129dc169f0b300c825362f7a7b.png) . Les opérateurs
d’évolution incrémentale et d’observation sont donc respectivement les
opérateurs augmentés et , et sont
directement utilisables dans les cas d’études avec ADAO.
. Les opérateurs
d’évolution incrémentale et d’observation sont donc respectivement les
opérateurs augmentés et , et sont
directement utilisables dans les cas d’études avec ADAO.
2.9.5. Schéma conceptuel pour l’assimilation de données en dynamique¶
Pour compléter la description, on peut représenter la démarche d’assimilation
de données de manière spécifiquement dynamique à l’aide d’un schéma temporel,
qui décrit l’action des opérateurs d’évolution ( ou )
et d’observation ( ou ) lors de la simulation et
l’estimation récursive discrète de l’état (). Une
représentation simple est la suivante, particulièrement adaptée aux algorithmes
itératifs de filtrage de type Kalman :

Fig. 2.1 Schéma temporel d’action des opérateurs pour l’assimilation de données en dynamique¶
avec P la covariance d’erreur d’état et t le temps itératif discret. Dans ce schéma, l’analyse (x,P) est obtenue à travers la « correction » par l’observation de la « prévision » de l’état précédent. Une autre manière de comprendre l’assimilation de données dynamique, en observant les états dans l’espace des mesures, consiste à représenter sous la forme suivante la même démarche séquentielle d’assimilation que dans la figure précédente :

Fig. 2.2 Schéma séquentiel de l’état et des mesures pour l’assimilation de données en dynamique¶
Les concepts décrits dans ce schéma peuvent directement et simplement être utilisés dans ADAO pour comprendre et construire des cas d’études, et sont repris dans la description et les exemples de certains algorithmes.