13.17. Algorithme de calcul « UnscentedKalmanFilter »¶
13.17.1. Description¶
Cet algorithme réalise une estimation de l’état d’un système dynamique par un filtre de Kalman utilisant une transformation « unscented » et un échantillonnage par points « sigma », permettant d’éviter de devoir calculer les opérateurs tangent ou adjoint pour les opérateurs d’observation ou d’évolution, comme dans les filtres de Kalman simple ou étendu.
Il s’applique aux cas d’opérateurs d’observation et d’évolution incrémentale (processus) non-linéaires et présente d’excellentes qualités de robustesse et de performances. Il peut être rapproché de l”Algorithme de calcul « EnsembleKalmanFilter », dont les qualités sont similaires pour les systèmes non-linéaires.
On remarque qu’il n’y a pas d’analyse effectuée au pas de temps initial (numéroté 0 dans l’indexage temporel) car il n’y a pas de prévision à cet instant (l’ébauche est stockée comme pseudo-analyse au pas initial). Si les observations sont fournies en série par l’utilisateur, la première n’est donc pas utilisée. Pour une bonne compréhension de la gestion du temps, on se reportera au Schéma temporel d’action des opérateurs pour l’assimilation de données en dynamique et aux explications décrites dans la section pour Approfondir l’assimilation de données pour la dynamique.
Dans le cas d’opérateurs linéaires ou « faiblement » non-linéaire, on peut aisément utiliser l”Algorithme de calcul « ExtendedKalmanFilter » ou même l”Algorithme de calcul « KalmanFilter », qui sont souvent largement moins coûteux en évaluation sur de petits systèmes. On peut vérifier la linéarité des opérateurs à l’aide de l”Algorithme de vérification « LinearityTest ».
Il existe diverses variantes de cet algorithme. On propose ici les formulations stables et robustes suivantes :
« UKF » (Unscented Kalman Filter, voir [Julier95], [Julier00], [Wan00]), algorithme canonique d’origine et de référence, très robuste et performant,
« CUKF », aussi nommée « 2UKF » (Constrained Unscented Kalman Filter, voir [Julier07]), version avec contraintes d’inégalités ou de bornes de l’algorithme « UKF »,
« S3F » (Scaled Spherical Simplex Filter, voir [Papakonstantinou22]), algorithme amélioré, réduisant le nombre de (sigma) points d’échantillonnage pour avoir la même qualité que la variante « UKF » canonique,
« CS3F » (Constrained Scaled Spherical Simplex Filter), version avec contraintes d’inégalités ou de bornes de l’algorithme « S3F ».
Voici quelques suggestions pratiques pour une utilisation efficace de ces algorithmes :
La variante recommandée de cet algorithme est le « S3F », même si l’algorithme canonique « UKF » reste par défaut le plus robuste.
Lorsqu’il n’y a aucune borne de définie, les versions avec prise en compte des contraintes des algorithmes (« CUKF » et « CS3F ») sont identiques aux versions sans contraintes (« UKF » et « S3F »). Ce n’est pas le cas s’il a des contraintes définies, mêmes si les bornes choisies sont très larges.
Une différence essentielle entre les algorithmes est le nombre de « sigma » points d’échantillonnage utilisés en fonction de la dimension
 de
l’espace des états. L’algorithme canonique « UKF » en utilise
de
l’espace des états. L’algorithme canonique « UKF » en utilise 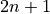 ,
l’algorithme « S3F » en utilise
,
l’algorithme « S3F » en utilise 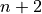 . Cela signifie qu’il faut de
l’ordre de deux fois plus d’évaluations de la fonction à simuler pour l’une
que l’autre.
. Cela signifie qu’il faut de
l’ordre de deux fois plus d’évaluations de la fonction à simuler pour l’une
que l’autre.Les évaluations de la fonction à simuler sont algorithmiquement indépendantes à chaque étape du filtrage (évolution ou observation) et peuvent donc être parallélisées ou distribuées dans le cas où la fonction à simuler le supporte.
13.17.2. Quelques propriétés notables des méthodes implémentées¶
Pour compléter la description on synthétise ici quelques propriétés notables, des méthodes de l’algorithme ou de leurs implémentations. Ces propriétés peuvent avoir une influence sur la manière de l’utiliser ou sur ses performances de calcul. Pour de plus amples renseignements, on se reportera aux références plus complètes indiquées à la fin du descriptif de cet algorithme.
Les méthodes d’optimisation proposées par cet algorithme effectuent une recherche locale du minimum, permettant en théorie d’atteindre un état localement optimal (par opposition à un état « globalement optimal »).
Les méthodes proposées par cet algorithme ne requièrent pas de dérivation de la fonction objectif ou de l’un des opérateurs, permettant d’éviter ce temps de calcul supplémentaire dans le cas où les dérivées sont calculées numériquement par de multiples évaluations.
Les méthodes proposées par cet algorithme présentent un parallélisme interne, et peuvent donc profiter de ressources informatiques de répartition de calculs. L’interaction potentielle, entre le parallélisme interne des méthodes, et le parallélisme éventuellement présent dans les opérateurs d’observation ou d’évolution intégrant les codes de l’utilisateur, doit donc être soigneusement réglée.
Les méthodes proposées par cet algorithme atteignent leur convergence sur un ou plusieurs critères statiques, fixés par des propriétés algorithmiques particulières. En pratique, il peut y avoir plusieurs critères de convergence actifs simultanément.
La propriété algorithmique la plus courante est celle des calculs directs, qui évaluent la solution à convergence sans itération contrôlable. Il n’y a aucun seuil de convergence à régler dans ce cas.
13.17.3. Commandes requises et optionnelles¶
Les commandes générales requises, disponibles en édition dans l’interface graphique ou textuelle, sont les suivantes :
- Background
Vecteur. La variable désigne le vecteur d’ébauche ou d’initialisation, usuellement noté
 . Sa valeur est définie comme un objet
de type « Vector » ou « VectorSerie ». Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est définie comme un objet
de type « Vector » ou « VectorSerie ». Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- BackgroundError
Matrice. La variable désigne la matrice de covariance des erreurs d’ébauche, usuellement notée
 . Sa valeur est définie comme
un objet de type « Matrix », de type « ScalarSparseMatrix », ou de type
« DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est définie comme
un objet de type « Matrix », de type « ScalarSparseMatrix », ou de type
« DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- EvolutionError
Matrice. La variable désigne la matrice de covariance des erreurs a priori d’évolution, usuellement notée
 . Sa valeur est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- EvolutionModel
Opérateur. La variable désigne l’opérateur d’évolution du modèle, usuellement noté
 , qui décrit un pas élémentaire d’évolution
dynamique ou itérative. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle
, qui décrit un pas élémentaire d’évolution
dynamique ou itérative. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle  est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire
est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire  .
.
- Observation
Liste de vecteurs. La variable désigne le vecteur d’observation utilisé en assimilation de données ou en optimisation, et usuellement noté
 . Sa valeur est définie comme un objet de type « Vector »
si c’est une unique observation (temporelle ou pas) ou « VectorSerie » si
c’est une succession d’observations. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est définie comme un objet de type « Vector »
si c’est une unique observation (temporelle ou pas) ou « VectorSerie » si
c’est une succession d’observations. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- ObservationError
Matrice. La variable désigne la matrice de covariance des erreurs a priori d’ébauche, usuellement notée
 . Cette matrice est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Cette matrice est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- ObservationOperator
Opérateur. La variable désigne l’opérateur d’observation, usuellement noté
 , qui transforme les paramètres d’entrée
, qui transforme les paramètres d’entrée  en
résultats
en
résultats  qui sont à comparer aux observations
. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle
est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire .
qui sont à comparer aux observations
. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle
est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire .
Les commandes optionnelles générales, disponibles en édition dans l’interface graphique ou textuelle, sont indiquées dans la Liste des commandes et mots-clés pour un cas d’assimilation de données ou d’optimisation. De plus, les paramètres de la commande « AlgorithmParameters » permettent d’indiquer les options particulières, décrites ci-après, de l’algorithme. On se reportera à la Description des options d’un algorithme par « AlgorithmParameters » pour le bon usage de cette commande.
Les options sont les suivantes :
- Bounds
Liste de paires de valeurs réelles. Cette clé permet de définir des paires de bornes supérieure et inférieure pour chaque variable d’état optimisée. Les bornes doivent être données par une liste de liste de paires de bornes inférieure/supérieure pour chaque variable, avec une valeur
Nonechaque fois qu’il n’y a pas de borne. Les bornes peuvent toujours être spécifiées, mais seuls les optimiseurs sous contraintes les prennent en compte. Si la liste est vide, cela équivaut à une absence de bornes.Exemple :
{"Bounds":[[2.,5.],[1.e-2,10.],[-30.,None],[None,None]]}
- ConstrainedBy
Nom prédéfini. Cette clé permet d’indiquer la méthode de prise en compte des contraintes de bornes. La seule disponible est « EstimateProjection », qui projette l’estimation de l’état courant sur les contraintes de bornes.
Exemple :
{"ConstrainedBy":"EstimateProjection"}
- EstimationOf
Nom prédéfini. Cette clé permet de choisir le type d’estimation à réaliser. Cela peut être soit une estimation de l’état, avec la valeur « State », ou une estimation de paramètres, avec la valeur « Parameters ». Le choix par défaut est « State ».
Exemple :
{"EstimationOf":"State"}
- Alpha, Beta, Kappa, Reconditioner
Valeurs réelles ou entières. Ces clés sont des paramètres de mise à l’échelle interne. « Alpha » requiert une valeur comprise entre 1.e-4 et 1. « Beta » a une valeur optimale de 2 pour une distribution a priori gaussienne. « Kappa » requiert une valeur entière, dont la bonne valeur par défaut est obtenue en la mettant à 0. « Reconditioner » requiert une valeur comprise entre 1.e-3 et 10, son défaut étant 1.
Exemple :
{"Alpha":1,"Beta":2,"Kappa":0,"Reconditioner":1}- StoreSupplementaryCalculations
Liste de noms. Cette liste indique les noms des variables supplémentaires, qui peuvent être disponibles au cours du déroulement ou à la fin de l’algorithme, si elles sont initialement demandées par l’utilisateur. Leur disponibilité implique, potentiellement, des calculs ou du stockage coûteux. La valeur par défaut est donc une liste vide, aucune de ces variables n’étant calculée et stockée par défaut (sauf les variables inconditionnelles). Les noms possibles pour les variables supplémentaires sont dans la liste suivante (la description détaillée de chaque variable nommée est donnée dans la suite de cette documentation par algorithme spécifique, dans la sous-partie « Informations et variables disponibles à la fin de l’algorithme ») : [ « Analysis », « APosterioriCorrelations », « APosterioriCovariance », « APosterioriStandardDeviations », « APosterioriVariances », « BMA », « CostFunctionJ », « CostFunctionJAtCurrentOptimum », « CostFunctionJb », « CostFunctionJbAtCurrentOptimum », « CostFunctionJo », « CostFunctionJoAtCurrentOptimum », « CurrentOptimum », « CurrentState », « CurrentStepNumber », « EnsembleOfSimulations », « EnsembleOfStates », « ForecastCovariance », « ForecastState », « IndexOfOptimum », « InnovationAtCurrentAnalysis », « InnovationAtCurrentState », « SimulatedObservationAtCurrentAnalysis », « SimulatedObservationAtCurrentOptimum », « SimulatedObservationAtCurrentState », ].
Exemple :
{"StoreSupplementaryCalculations":["CurrentState", "Residu"]}
- Variant
Nom prédéfini. Cette clé permet de choisir l’une des variantes possibles pour l’algorithme principal. La variante par défaut est la version contrainte « CUKF/2UKF » de l’algorithme original « UKF », et les choix possibles sont « UKF » (Unscented Kalman Filter), « CUKF » ou « 2UKF » (Constrained Unscented Kalman Filter), « S3F » (Scaled Spherical Simplex Filter), « CS3F » (Constrained Scaled Spherical Simplex Filter). Il est fortement recommandé de conserver la valeur par défaut.
Exemple :
{"Variant":"2UKF"}
13.17.4. Informations et variables disponibles à la fin de l’algorithme¶
En sortie, après exécution de l’algorithme, on dispose d’informations et de
variables issues du calcul. La description des
Variables et informations disponibles en sortie indique la manière de les obtenir, par la
méthode nommée get, depuis la variable « ADD » du post-processing en
interface graphique, ou depuis le cas en interface textuelle. Les variables
d’entrée, mises à disposition de l’utilisateur en sortie pour faciliter
l’écriture des procédures de post-processing, sont décrites dans un
Inventaire des informations potentiellement disponibles en sortie.
Sorties permanentes (non conditionnelles)
Les sorties non conditionnelles de l’algorithme sont les suivantes :
- Analysis
Liste de vecteurs. Chaque élément de cette variable est un état optimal
 en optimisation, une interpolation ou une analyse
en optimisation, une interpolation ou une analyse
 en assimilation de données.
en assimilation de données.Exemple :
xa = ADD.get("Analysis")[-1]
Ensemble des sorties à la demande (conditionnelles ou non)
L’ensemble des sorties (conditionnelles ou non) de l’algorithme, classées par ordre alphabétique, est le suivant :
- Analysis
Liste de vecteurs. Chaque élément de cette variable est un état optimal
en optimisation, une interpolation ou une analyse
en assimilation de données.Exemple :
xa = ADD.get("Analysis")[-1]
- APosterioriCorrelations
Liste de matrices. Chaque élément est une matrice de corrélations des erreurs a posteriori de l’état optimal, issue de la matrice
 des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.
des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.Exemple :
apc = ADD.get("APosterioriCorrelations")[-1]
- APosterioriCovariance
Liste de matrices. Chaque élément est une matrice
de
covariances des erreurs a posteriori de l’état optimal.Exemple :
apc = ADD.get("APosterioriCovariance")[-1]
- APosterioriStandardDeviations
Liste de matrices. Chaque élément est une matrice diagonale d’écarts-types des erreurs a posteriori de l’état optimal, issue de la matrice
des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.Exemple :
aps = ADD.get("APosterioriStandardDeviations")[-1]
- APosterioriVariances
Liste de matrices. Chaque élément est une matrice diagonale de variances des erreurs a posteriori de l’état optimal, issue de la matrice
des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.Exemple :
apv = ADD.get("APosterioriVariances")[-1]
- BMA
Liste de vecteurs. Chaque élément est un vecteur d’écart entre l’ébauche et l’état optimal.
Exemple :
bma = ADD.get("BMA")[-1]
- CostFunctionJ
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
 choisie.
choisie.Exemple :
J = ADD.get("CostFunctionJ")[:]
- CostFunctionJAtCurrentOptimum
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
. A chaque pas, la valeur correspond à l’état optimal trouvé depuis
le début.Exemple :
JACO = ADD.get("CostFunctionJAtCurrentOptimum")[:]
- CostFunctionJb
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
 , c’est-à-dire de la partie écart à l’ébauche. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.
, c’est-à-dire de la partie écart à l’ébauche. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.Exemple :
Jb = ADD.get("CostFunctionJb")[:]
- CostFunctionJbAtCurrentOptimum
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
, c’est-à-dire de la partie écart à l’ébauche. A chaque pas, la
valeur correspond à l’état optimal trouvé depuis le début. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.Exemple :
JbACO = ADD.get("CostFunctionJbAtCurrentOptimum")[:]
- CostFunctionJo
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
 , c’est-à-dire de la partie écart à l’observation.
, c’est-à-dire de la partie écart à l’observation.Exemple :
Jo = ADD.get("CostFunctionJo")[:]
- CostFunctionJoAtCurrentOptimum
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
, c’est-à-dire de la partie écart à l’observation. A chaque pas,
la valeur correspond à l’état optimal trouvé depuis le début.Exemple :
JoACO = ADD.get("CostFunctionJoAtCurrentOptimum")[:]
- CurrentOptimum
Liste de vecteurs. Chaque élément est le vecteur d’état optimal au pas de temps courant au cours du déroulement itératif de l’algorithme d’optimisation utilisé. Ce n’est pas nécessairement le dernier état.
Exemple :
xo = ADD.get("CurrentOptimum")[:]
- CurrentState
Liste de vecteurs. Chaque élément est un vecteur d’état courant utilisé au cours du déroulement itératif de l’algorithme utilisé.
Exemple :
xs = ADD.get("CurrentState")[:]
- CurrentStepNumber
Liste d’entiers. Chaque élément est l’index du pas courant au cours du déroulement itératif, piloté par la série des observations, de l’algorithme utilisé. Cela correspond au pas d’observation utilisé. Remarque : ce n’est pas l’index d’itération courant d’algorithme même si cela coïncide pour des algorithmes non itératifs.
Exemple :
csn = ADD.get("CurrentStepNumber")[-1]
- EnsembleOfSimulations
Liste de vecteurs ou matrice. Chaque élément est une collection ordonnée de vecteurs d’état physique ou d’état simulé éventuellement observé
. Ce sont des sorties d’opérateur ,
c’est-à-dire des états d’observation simulés (nommés « snapshots » en
terminologie de bases réduites). A chaque index de pas, il y a 1 état par
colonne si cette liste est sous forme matricielle, ou 1 état par élément si
c’est effectivement une liste. Important : la numérotation du support ou des
points, sur lequel ou auxquels sont fournis une valeur d’état dans chaque
vecteur, est implicitement celle de l’ordre naturel de numérotation du
vecteur d’état, de 0 à la « taille moins 1 » de ce vecteur.Exemple :
{"EnsembleOfSimulations":[y1, y2, y3...]}
- EnsembleOfStates
Liste de vecteurs ou matrice. Chaque élément est une collection ordonnée de vecteurs d’état physique ou d’état paramétrique
. Ce sont
des entrées d’opérateur , c’est-à-dire des états courants avant
observation. A chaque index de pas, il y a 1 état par colonne si cette liste
est sous forme matricielle, ou 1 état par élément si c’est effectivement une
liste. Important : la numérotation du support ou des points, sur lequel ou
auxquels sont fournis une valeur d’état dans chaque vecteur, est
implicitement celle de l’ordre naturel de numérotation du vecteur d’état, de
0 à la « taille moins 1 » de ce vecteur.Exemple :
{"EnsembleOfStates":[x1, x2, x3...]}
- ForecastCovariance
Liste de matrices. Chaque élément est une matrice de covariance d’erreur sur l’état prévu par le modèle au cours du déroulement itératif temporel de l’algorithme utilisé.
Exemple :
pf = ADD.get("ForecastCovariance")[-1]
- ForecastState
Liste de vecteurs. Chaque élément est un vecteur d’état (ou un ensemble de vecteurs d’états selon l’algorithme) prévu(s) par le modèle au cours du déroulement itératif temporel de l’algorithme utilisé.
Exemple :
xf = ADD.get("ForecastState")[:]
- IndexOfOptimum
Liste d’entiers. Chaque élément est l’index d’itération de l’optimum obtenu au cours du déroulement itératif de l’algorithme d’optimisation utilisé. Ce n’est pas nécessairement le numéro de la dernière itération.
Exemple :
ioo = ADD.get("IndexOfOptimum")[-1]
- InnovationAtCurrentAnalysis
Liste de vecteurs. Chaque élément est un vecteur d’innovation à l’état analysé courant. Cette quantité est identique au vecteur d’innovation à l’état analysé dans le cas d’une assimilation mono-état.
Exemple :
da = ADD.get("InnovationAtCurrentAnalysis")[-1]
- InnovationAtCurrentState
Liste de vecteurs. Chaque élément est un vecteur d’innovation à l’état courant avant analyse.
Exemple :
ds = ADD.get("InnovationAtCurrentState")[-1]
- SimulatedObservationAtCurrentAnalysis
Liste de vecteurs. Chaque élément est un vecteur d’observation simulé par l’opérateur d’observation à partir de l’état courant, c’est-à-dire dans l’espace des observations. Cette quantité est identique au vecteur d’observation simulé à l’état courant dans le cas d’une assimilation mono-état.
Exemple :
hxs = ADD.get("SimulatedObservationAtCurrentAnalysis")[-1]
- SimulatedObservationAtCurrentOptimum
Liste de vecteurs. Chaque élément est un vecteur d’observation simulé par l’opérateur d’observation à partir de l’état optimal au pas de temps courant au cours du déroulement de l’algorithme d’optimisation, c’est-à-dire dans l’espace des observations.
Exemple :
hxo = ADD.get("SimulatedObservationAtCurrentOptimum")[-1]
- SimulatedObservationAtCurrentState
Liste de vecteurs. Chaque élément est un vecteur d’observation simulé par l’opérateur d’observation à partir de l’état courant, c’est-à-dire dans l’espace des observations.
Exemple :
hxs = ADD.get("SimulatedObservationAtCurrentState")[-1]