13.13. Algorithme de calcul « ParticleSwarmOptimization »¶
13.13.1. Description¶
Cet algorithme réalise une estimation de l’état d’un système, par minimisation
d’une fonctionnelle d’écart  , en utilisant une méthode évolutionnaire
d’essaim particulaire. C’est une méta-heuristique qui ne requiert pas
d’information particulière sur la fonctionnelle et qui ne nécessite pas les
dérivées (sauf dans sa version hybride de type « VLS »).
, en utilisant une méthode évolutionnaire
d’essaim particulaire. C’est une méta-heuristique qui ne requiert pas
d’information particulière sur la fonctionnelle et qui ne nécessite pas les
dérivées (sauf dans sa version hybride de type « VLS »).
Elle entre dans la même catégorie que les Algorithme de calcul « DerivativeFreeOptimization », Algorithme de calcul « DifferentialEvolution », Algorithme de calcul « SimulatedAnnealing », Algorithme de calcul « TabuSearch ».
C’est une méthode d’optimisation mono-objectif, permettant la recherche du
minimum global d’une fonctionnelle d’erreur quelconque de type
 ,
,  ou
ou  , avec ou sans pondérations,
comme décrit dans la section pour Approfondir l’estimation d’état par des méthodes d’optimisation. Comme
c’est une méta-heuristique d’optimisation, l’atteinte d’un résultat optimal
global ou local n’est pas garantie (sauf dans sa version hybride de type
« VLS »). La fonctionnelle d’erreur par défaut est celle de moindres carrés
pondérés augmentés, classiquement utilisée en assimilation de données.
, avec ou sans pondérations,
comme décrit dans la section pour Approfondir l’estimation d’état par des méthodes d’optimisation. Comme
c’est une méta-heuristique d’optimisation, l’atteinte d’un résultat optimal
global ou local n’est pas garantie (sauf dans sa version hybride de type
« VLS »). La fonctionnelle d’erreur par défaut est celle de moindres carrés
pondérés augmentés, classiquement utilisée en assimilation de données.
Elle est basée sur l’évolution d’une population (appelée « essaim ») d’états (chaque individu étant appelé une « particule » ou un « insecte »). Il existe diverses variantes de cet algorithme. On propose ici les formulations stables et robustes suivantes :
« CanonicalPSO » (Canonical Particule Swarm Optimisation, voir [ZambranoBigiarini13]), algorithme classique dit « canonique » d’essaim particulaire, robuste et définissant une référence des algorithmes d’essaims particulaires,
« OGCR » (Simple Particule Swarm Optimisation), algorithme simplifié d’essaim particulaire sans bornes sur les insectes ou les vitesses, déconseillé car peu robuste, mais parfois beaucoup plus rapide,
« SPSO-2011 » ou « SPSO-2011-AIS » (Standard Particle Swarm Optimisation 2011, voir [ZambranoBigiarini13]), algorithme de référence 2011 d’essaim particulaire, robuste, performant et défini comme une référence des algorithmes d’essaims particulaires. Cet algorithme est parfois appelé «
 -PSO » ou « Inertia PSO » car il intègre une contribution dite
d’inertie, ou encore appelé « AIS » (pour « Asynchronous Iteration Strategy ») ou
« APSO » (pour « Advanced Particle Swarm Optimisation ») car il intègre la mise à
jour évolutive des meilleurs éléments, conduisant à une convergence
intrinsèquement améliorée de l’algorithme,
-PSO » ou « Inertia PSO » car il intègre une contribution dite
d’inertie, ou encore appelé « AIS » (pour « Asynchronous Iteration Strategy ») ou
« APSO » (pour « Advanced Particle Swarm Optimisation ») car il intègre la mise à
jour évolutive des meilleurs éléments, conduisant à une convergence
intrinsèquement améliorée de l’algorithme,« SPSO-2011-SIS » (Standard Particle Swarm Optimisation 2011 with Synchronous Iteration Strategy), très similaire à l’algorithme de référence 2011 et avec une mise à jour synchrone, appelée « SIS », des particules,
« SPSO-2011-PSIS » (Standard Particle Swarm Optimisation 2011 with Parallel Synchronous Iteration Strategy), similaire à l’algorithme « SPSO-2011-SIS » avec mise à jour synchrone et parallélisation, appelée « PSIS », des particules.
Chacune des méthodes ci-dessus peut voir l’aspect local de sa recherche accéléré par une méthode variationnelle « VLS » (Variational Local Search) concernant les meilleurs insectes de l’essaim. L’aspect global de la recherche reste préservé par la méthode d’essaim particulaire, mais il convient expérimentalement d’être très attentif à éviter la stagnation prématurée des meilleurs particules de l’essaim. Il suffit de suffixer le nom de la variante d’algorithme par « -VLS » pour activer l’accélération, comme par exemple « CanonicalPSO-VLS ».
Voici quelques suggestions pratiques pour une utilisation efficace de ces algorithmes :
La variante recommandée de cet algorithme est le « SPSO-2011 » même si l’algorithme « CanonicalPSO » reste par défaut le plus robuste. Dans le cas où l’évaluation de l’état peut être réalisé en parallèle, on peut utiliser l’algorithme « SPSO-2011-PSIS » même si sa convergence est parfois un peu moins performante.
Le nombre de particules ou d’insectes usuellement recommandé varie entre 40 et 100 selon l’algorithme, à peu près indépendamment de la dimension de l’espace des états. En général, les meilleurs performances sont obtenues pour des populations de 70 à 500 particules. Même si la valeur par défaut de ce paramètre de base provient d’une expérience étendue sur ces algorithmes, il est recommandé de l’adapter à la difficulté des problèmes traités.
Le nombre recommandé de générations, lors de l’évolution de la population, est souvent de l’ordre de 50, mais il peut facilement varier entre 25 et 500.
Le nombre maximal d’évaluation de la fonction de simulation doit usuellement être limité entre quelques milliers et quelques dizaines de milliers de fois la dimension de l’espace des états.
La fonctionnelle d’erreur décroît usuellement par pallier (donc avec une progression nulle de la valeur de fonctionnelle à chaque génération lorsque l’on reste dans le palier), rendant non recommandé un arrêt sur critère de décroissance de la fonction-coût. Il est normalement plus judicieux d’adapter le nombre d’itérations ou de générations pour accélérer la convergence des algorithmes.
Si le problème est contraint, il faut définir les bornes des variables (par la variable « Bounds »). Si le problème est totalement non contraint, il est indispensable de définir des bornes d’incrément (par la variable « BoxBounds ») pour circonscrire la recherche optimale de manière utile. De manière similaire, si le problème est partiellement contraint, il est recommandé (mais pas indispensable) de définir des bornes d’incrément. Dans le cas où ces bornes d’incréments ne sont pas définies, ce sont les bornes des variables qui seront utilisées comme bornes d’incréments.
L’usage des variantes hybrides d’accélération de type « VLS » va requérir la disponibilité du gradient de l’opérateur (soit donné explicitement soit demandé par différences finies à la définition), mais accélère normalement la recherche locale. Il est donc judicieux de réduire notablement le nombre de générations (qui peut être parfois réduit jusqu’à seulement 5 ou 10) tout en spécifiant bien un nombre raisonnable d’insectes (de l’ordre par exemple de 1 à 5) faisant l’objet de cette recherche locale. Les paramètres de la recherche hybride sont néanmoins à adapter finement pour chaque cas, sous forme d’un compromis, pour disposer à la fois de la capacité globale et locale de cette optimisation. En effet, une convergence locale trop rapide ou une exploration globale trop restreinte peut réduire la capacité algorithmique à bien explorer l’espace des solutions.
Ces conseils sont à utiliser comme des indications expérimentales, et non comme des prescriptions, car ils sont à apprécier ou à adapter selon la physique de chaque problème que l’on traite.
Le décompte du nombre d’évaluations de la fonction à simuler lors de cet algorithme est déterministe, à savoir le « nombre d’itérations ou de générations » multiplié par le « nombre d’individus de la population ». Avec les valeurs par défaut de 40 à 100 individus sur 50 générations, il faut entre 40x50=2000 et 100*50=5000 évaluations par défaut, ce qui est notablement plus qu’en optimisation variationnelle. C’est pour cette raison que cet algorithme est usuellement intéressant lorsque la dimension de l’espace des états est grande, ou que les non-linéarités de la simulation rendent compliqué, ou invalide, l’évaluation du gradient de la fonctionnelle par approximation numérique. Mais il est aussi nécessaire que le calcul de la fonction à simuler ne soit pas trop coûteux pour éviter une durée d’optimisation rédhibitoire.
Pour réduire le nombre de générations, on peut utiliser la méthode adaptative ASAPSO [Wang09] de modification de la localisation de la recherche optimale de l’essaim. Elle consiste à réduire linéairement la propension à la recherche globale de l’algorithme, et donc à favoriser la localisation de l’essaim. Lorsque le problème s’y prête, il est possible de réduire d’un facteur 2 à 5 le nombre de générations tout en obtenant une qualité sensiblement identique pour la meilleure particule. Deux mots-clés sont disponibles pour contrôler l’usage de cette méthode adaptative.
Comme pour d’autres algorithmes, il est possible de calculer une quantité appelée la covariance a posteriori de l’essaim des particules. Néanmoins la signification de l’indicateur calculé ici diffère par nature d’une covariance établie par exemple en filtrage ou en variationnel. L’indicateur est calculé, de manière standard, comme la dispersion de l’ensemble des particules. Mais sa valeur est exclusivement à comparer à l’évaluation de cette même quantité pour l’essaim initial, et à utiliser dans un sens relatif de variation entre le début et la fin de la recherche optimale de l’algorithme. En effet, la dispersion initiale des particules est contrôlée par les paramètres d’initialisation de l’essaim dont le but est de couvrir l’espace de recherche, et la dispersion finale des particules reflète la performance de la localisation de la recherche optimale. Contrairement à la covariance des erreurs d’ébauche, qui intervient classiquement dans le calcul de l’objectif à optimiser et qui est liée à la variance de l’état optimal, la covariance calculée a posteriori ne reflète que la dispersion des particules. Pour l’usage correct de cet algorithme, lorsque le calcul de la covariance a posteriori est demandé, il est effectué pour l’essaim initial et pour l’essaim final.
13.13.2. Quelques propriétés notables des méthodes implémentées¶
Pour compléter la description on synthétise ici quelques propriétés notables, des méthodes de l’algorithme ou de leurs implémentations. Ces propriétés peuvent avoir une influence sur la manière de l’utiliser ou sur ses performances de calcul. Pour de plus amples renseignements, on se reportera aux références plus complètes indiquées à la fin du descriptif de cet algorithme.
Les méthodes d’optimisation proposées par cet algorithme effectuent une recherche non locale du minimum, sans pour autant néanmoins assurer une recherche globale. C’est le cas lorsque les méthodes d’optimisation de recherche locale présentent de plus des capacités permettant d’éviter de rester bloquées par le premier minimum local trouvé. Ces capacités sont parfois heuristiques.
Les méthodes proposées par cet algorithme ne requièrent pas de dérivation de la fonction objectif ou de l’un des opérateurs, permettant d’éviter ce temps de calcul supplémentaire dans le cas où les dérivées sont calculées numériquement par de multiples évaluations.
Les méthodes proposées par cet algorithme présentent un parallélisme interne, et peuvent donc profiter de ressources informatiques de répartition de calculs. L’interaction potentielle, entre le parallélisme interne des méthodes, et le parallélisme éventuellement présent dans les opérateurs d’observation ou d’évolution intégrant les codes de l’utilisateur, doit donc être soigneusement réglée.
Les méthodes proposées par cet algorithme atteignent leur convergence sur un ou plusieurs critères de nombre. En pratique, il peut y avoir plusieurs critères de convergence actifs simultanément.
Le nombre est fréquemment un élément remarquable lié à l’algorithme, comme un nombre d’itérations ou un nombre d’évaluations, mais cela peut aussi être, par exemple, un nombre de générations pour un algorithme évolutionnaire.
Il convient de régler soigneusement les seuils de convergence, pour limiter le coût calcul global de l’algorithme, ou pour assurer une adaptation de la convergence au cas physique traité.
13.13.3. Commandes requises et optionnelles¶
Les commandes générales requises, disponibles en édition dans l’interface graphique ou textuelle, sont les suivantes :
- Background
Vecteur. La variable désigne le vecteur d’ébauche ou d’initialisation, usuellement noté
 . Sa valeur est définie comme un objet
de type « Vector » ou « VectorSerie ». Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est définie comme un objet
de type « Vector » ou « VectorSerie ». Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- BackgroundError
Matrice. La variable désigne la matrice de covariance des erreurs d’ébauche, usuellement notée
 . Sa valeur est définie comme
un objet de type « Matrix », de type « ScalarSparseMatrix », ou de type
« DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est définie comme
un objet de type « Matrix », de type « ScalarSparseMatrix », ou de type
« DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- EvolutionError
Matrice. La variable désigne la matrice de covariance des erreurs a priori d’évolution, usuellement notée
 . Sa valeur est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- EvolutionModel
Opérateur. La variable désigne l’opérateur d’évolution du modèle, usuellement noté
 , qui décrit un pas élémentaire d’évolution
dynamique ou itérative. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle
, qui décrit un pas élémentaire d’évolution
dynamique ou itérative. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle  est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire
est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire  .
.
- Observation
Liste de vecteurs. La variable désigne le vecteur d’observation utilisé en assimilation de données ou en optimisation, et usuellement noté
 . Sa valeur est définie comme un objet de type « Vector »
si c’est une unique observation (temporelle ou pas) ou « VectorSerie » si
c’est une succession d’observations. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est définie comme un objet de type « Vector »
si c’est une unique observation (temporelle ou pas) ou « VectorSerie » si
c’est une succession d’observations. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- ObservationError
Matrice. La variable désigne la matrice de covariance des erreurs a priori d’ébauche, usuellement notée
 . Cette matrice est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Cette matrice est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- ObservationOperator
Opérateur. La variable désigne l’opérateur d’observation, usuellement noté
 , qui transforme les paramètres d’entrée
, qui transforme les paramètres d’entrée  en
résultats
en
résultats  qui sont à comparer aux observations
. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle
est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire .
qui sont à comparer aux observations
. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle
est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire .
Les commandes optionnelles générales, disponibles en édition dans l’interface graphique ou textuelle, sont indiquées dans la Liste des commandes et mots-clés pour un cas d’assimilation de données ou d’optimisation. De plus, les paramètres de la commande « AlgorithmParameters » permettent d’indiquer les options particulières, décrites ci-après, de l’algorithme. On se reportera à la Description des options d’un algorithme par « AlgorithmParameters » pour le bon usage de cette commande.
Les options sont les suivantes :
- Bounds
Liste de paires de valeurs réelles. Cette clé permet de définir des paires de bornes supérieure et inférieure pour chaque variable d’état optimisée. Les bornes doivent être données par une liste de liste de paires de bornes inférieure/supérieure pour chaque variable, avec une valeur
Nonechaque fois qu’il n’y a pas de borne. Les bornes peuvent toujours être spécifiées, mais seuls les optimiseurs sous contraintes les prennent en compte. Si la liste est vide, cela équivaut à une absence de bornes.Exemple :
{"Bounds":[[2.,5.],[1.e-2,10.],[-30.,None],[None,None]]}
- BoxBounds
Liste de paires de valeurs réelles. Cette clé permet de définir des paires de bornes supérieure et inférieure pour chaque incrément de variable d’état optimisée (et non pas chaque variable d’état elle-même, dont les bornes peuvent être indiquées par la variable « Bounds »). Les bornes d’incréments doivent être données par une liste de liste de paires de bornes inférieure/supérieure pour chaque incrément de variable, avec une valeur
Nonechaque fois qu’il n’y a pas de borne. Cette clé est requise uniquement s’il n’y a pas de bornes de paramètres, et il n’y a pas de valeurs par défaut.Exemple :
{"BoxBounds":[[-0.5,0.5], [0.01,2.], [0.,None], [None,None]]}
- CognitiveAcceleration
Valeur réelle. Cette clé indique le taux de rappel vers la meilleure valeur connue précédemment de l’historique de l’insecte courant. C’est une valeur réelle positive. Le défaut est à peu près de
 et il
est recommandé de l’adapter, plutôt en le réduisant, au cas physique qui est
en traitement.
et il
est recommandé de l’adapter, plutôt en le réduisant, au cas physique qui est
en traitement.Dans le cas standard (non-adaptatif), ce taux est constant et vaut la valeur indiquée. Dans le cas adaptatif ASAPSO [Wang09], la valeur de cette clé indique le taux initial de rappel qui décroît ensuite linéairement selon le nombre de générations et le facteur associé « CognitiveAccelerationControl ».
Exemple :
{"CognitiveAcceleration":1.19315}
- CognitiveAccelerationControl
Valeur réelle. Cette clé indique le facteur de changement dans le taux de rappel vers la meilleure valeur connue précédemment de l’historique de l’insecte courant. C’est une valeur réelle positive dont le défaut est 0, c’est-à-dire que, par défaut, il n’y a aucun changement du taux de rappel.
Dans le cas adaptatif ASAPSO [Wang09], la valeur de cette clé indique le facteur de décroissance linéaire du taux de rappel avec le nombre de générations (rapporté au nombre total demandé de générations), sachant que la valeur initiale du taux est indiquée par le facteur associé « CognitiveAcceleration ». Il n’y a pas de valeur recommandée, mais on peut par exemple utiliser la valeur initiale
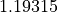 du facteur associé si
l’on veut annuler tout rappel vers la meilleure valeur connue de l’historique
à la fin des itérations.
du facteur associé si
l’on veut annuler tout rappel vers la meilleure valeur connue de l’historique
à la fin des itérations.Exemple :
{"CognitiveAccelerationControl":0.}
- DistributionByComponents
Liste de noms prédéfinis. Ce mot-clé n’a besoin d’être défini que lorsque l’initialisation de l’essaim de particules pour l’algorithme « ParticleSwarmOptimization » est fixée à « DistributionByComponents ». Dans ce cas, il faut indiquer, pour chaque composante de l’état, la distribution choisie sous la forme d’un nom prédéfini. Les noms possibles sont « uniform », « loguniform », « logarithmic », « [“normal”,σ] », « [“lognormal”,σ] » et « [“logarithmicnormal”,σ] ». Toutes les distributions « normal » doivent être accompagnées d’une indication d’écart-type σ, sachant qu’elles sont centrées dans le domaine de définition. Les valeurs « uniform », « loguniform », « normal », « lognormal » n’agissent que sur l’initialisation de la position en appliquant la distribution indiquée, les valeurs « logarithmic » et « logarithmicnormal » agissent à la fois sur l’initialisation de la position et celle du mouvement. Il doit y en avoir le même nombre de valeurs indiquées que la taille d’un état individuel. Les distributions se conforment aux bornes indiquées pour l’algorithme « *ParticleSwarmOptimization ». Les distributions peuvent être différentes pour chaque axe. Lorsque l’on choisi une distribution identique pour toutes les composantes, cela équivaut à choisir à la place la valeur globale du mot-clé précédent s’il existe.
Exemple :
{"DistributionByComponents" : ['uniform', 'loguniform', 'logarithmic', ['normal', 1]]}pour un espace d’état de dimension 4.
- GlobalCostReductionTolerance
Valeur réelle. Cette clé indique le facteur de réduction limite, conduisant à arrêter le processus itératif d’optimisation lorsque la fonction coût décroît au moins de cette tolérance sur l’ensemble de la recherche optimale. La valeur par défaut est de 1.e-16 (ce qui équivaut à une absence d’effet), et il est recommandé de l’adapter aux besoins pour des problèmes réels.
Exemple :
{"GlobalCostReductionTolerance":1.e-16}
- HybridCostDecrementTolerance
Valeur réelle. Cette clé indique une valeur limite, conduisant à arrêter le processus itératif d’optimisation dans la partie variationnelle du couplage, lorsque la fonction coût décroît moins que cette tolérance au dernier pas. Le défaut est de 1.e-7, et il est recommandé de l’adapter aux besoins pour des problèmes réels. On peut se reporter à la partie décrivant les manières de Contrôler la convergence pour des cas de calculs et algorithmes itératifs pour des recommandations plus détaillées.
Exemple :
{"HybridCostDecrementTolerance":1.e-7}
- HybridMaximumNumberOfIterations
Valeur entière. Cette clé indique le nombre maximum d’itérations internes possibles en optimisation hybride, pour la partie variationnelle. Le défaut est 15000, qui est très similaire à une absence de limite sur les itérations. Il est ainsi recommandé d’adapter ce paramètre aux besoins pour des problèmes réels. Pour certains optimiseurs, le nombre de pas effectif d’arrêt peut être légèrement différent de la limite à cause d’exigences de contrôle interne de l’algorithme. On peut se reporter à la partie décrivant les manières de Contrôler la convergence pour des cas de calculs et algorithmes itératifs pour des recommandations plus détaillées.
Exemple :
{"HybridMaximumNumberOfIterations":100}
- HybridNumberOfLocalHunters
Valeur entière. Cette clé indique le nombre d’insectes sur lesquels la recherche locale va être conduite. Les insectes sont choisis comme les meilleurs de l’itération courante de la recherche globale. Avec une valeur par défaut de 1, la recherche locale est effectuée uniquement sur le meilleur. Il est ainsi recommandé d’adapter ce paramètre aux besoins pour des problèmes réels.
Exemple :
{"HybridNumberOfLocalHunters":1}
- HybridNumberOfWarmupIterations
Valeur entière. Cette clé indique le nombre d’itérations initiales de la recherche globale effectuées avant d’établir une recherche locale sur les meilleurs insectes. Par défaut avec une valeur de 0, la recherche locale est effectuée dès le premier pas itératif de la recherche globale.
Exemple :
{"HybridNumberOfWarmupIterations":0}
- InertiaWeight
Valeur réelle. Cette clé indique la part de la vitesse de l’essaim qui est imposée à l’insecte, dite « poids de l’inertie ». C’est une valeur réelle comprise entre 0 et 1. Le défaut est de à peu près
 et il
est recommandé de l’adapter au cas physique qui est en traitement.
et il
est recommandé de l’adapter au cas physique qui est en traitement.Exemple :
{"InertiaWeight":0.72135}
- InitializationPoint
Vecteur. La variable désigne un vecteur à utiliser comme l’état initial autour duquel démarre un algorithme itératif. Par défaut, cet état initial n’a pas besoin d’être fourni et il est égal à l’ébauche
.
Sa valeur doit permettre de construire un vecteur de taille identique à
l’ébauche. Dans le cas où il est fourni, il ne remplace l’ébauche que pour
l’initialisation.Exemple :
{"InitializationPoint":[1, 2, 3, 4, 5]}
- MaximumNumberOfFunctionEvaluations
Valeur entière. Cette clé indique le nombre maximum d’évaluations possibles de la fonctionnelle à optimiser. Le défaut est de 15000, qui est une limite arbitraire. Il est ainsi recommandé d’adapter ce paramètre aux besoins pour des problèmes réels. Pour certains optimiseurs, le nombre effectif d’évaluations à l’arrêt peut être légèrement différent de la limite à cause d’exigences de déroulement interne de l’algorithme.
Exemple :
{"MaximumNumberOfFunctionEvaluations":50}
- MaximumNumberOfIterations
Valeur entière. Cette clé indique le nombre maximum d’itérations interne possibles en optimisation itérative. Le défaut est 50, qui est une limite arbitraire. Il est ainsi recommandé d’adapter ce paramètre aux besoins pour des problèmes réels.
Exemple :
{"MaximumNumberOfIterations":50}
- NumberOfInsects
Valeur entière. Cette clé indique le nombre d’insectes ou de particules dans l’essaim. La valeur par défaut est 100, qui est une valeur par défaut usuelle pour cet algorithme.
Exemple :
{"NumberOfInsects":100}
- QualityCriterion
Nom prédéfini. Cette clé indique le critère de qualité, qui est minimisé pour trouver l’estimation optimale de l’état. Le défaut est le critère usuel de l’assimilation de données nommé « DA », qui est le critère de moindres carrés pondérés augmentés. Le critère possible est dans la liste suivante, dans laquelle les noms équivalents sont indiqués par un signe « <=> » : [« AugmentedWeightedLeastSquares » <=> « AWLS » <=> « DA », « WeightedLeastSquares » <=> « WLS », « LeastSquares » <=> « LS » <=> « L2 », « AbsoluteValue » <=> « L1 », « MaximumError » <=> « ME » <=> « Linf »]. On pourra se reporter à la section pour Approfondir l’estimation d’état par des méthodes d’optimisation afin de disposer de la définition détaillée de ces critères de qualité.
Exemple :
{"QualityCriterion":"DA"}
- SetSeed
Valeur entière. Cette clé permet de donner un nombre entier pour fixer la graine du générateur aléatoire utilisé dans l’algorithme. Par défaut, la graine est laissée non initialisée, et elle utilise ainsi l’initialisation par défaut de l’ordinateur, qui varie donc à chaque étude. Pour assurer la reproductibilité de résultats impliquant des tirages aléatoires, il est fortement conseillé d’initialiser la graine. Une valeur simple est par exemple 123456789. Il est conseillé de mettre un entier à plus de 6 ou 7 chiffres pour bien initialiser le générateur aléatoire.
Exemple :
{"SetSeed":123456789}
- SocialAcceleration
Valeur réelle. Cette clé indique le taux de rappel vers le meilleur insecte du voisinage de l’insecte courant, qui est par défaut l’essaim complet. C’est une valeur réelle positive. Le défaut est à peu près de
et il est recommandé de l’adapter, plutôt en le
réduisant, au cas physique qui est en traitement.Dans le cas standard (non-adaptatif), ce taux est constant et vaut la valeur indiquée. Dans le cas adaptatif ASAPSO [Wang09], la valeur de cette clé indique le taux initial de rappel qui croît ensuite linéairement selon le nombre de générations et le facteur associé « SocialAccelerationControl ».
Exemple :
{"SocialAcceleration":1.19315}
- SocialAccelerationControl
Valeur réelle. Cette clé indique le facteur de changement dans le taux de rappel vers le meilleur insecte du voisinage de l’insecte courant, qui est par défaut l’essaim complet. C’est une valeur réelle positive dont le défaut est 0, c’est-à-dire que, par défaut, il n’y a aucun changement du taux de rappel.
Dans le cas adaptatif ASAPSO [Wang09], la valeur de cette clé indique le facteur de croissance linéaire du taux de rappel avec le nombre de générations (rapporté au nombre total demandé de générations), sachant que la valeur initiale du taux est indiquée par le facteur associé « SocialAcceleration ». Il n’y a pas de valeur recommandée, mais on peut par exemple utiliser la valeur initiale
du facteur associé si
l’on veut doubler le rappel vers la meilleure valeur connue du voisinage à la
fin des itérations.Exemple :
{"SocialAccelerationControl":0.}
- StoreInitialState
Valeur booléenne. Cette variable définit le stockage (avec True) ou pas (avec False, par défaut) de l’état initial de l’algorithme comme étant le premier état dans la suite itérative des états trouvés. Cela rend le stockage algorithmique itératif identique au stockage temporel itératif (de manière par exemple similaire aux filtres de Kalman).
Exemple :
{"StoreInitialState":False}
- SwarmInitialization
Nom prédéfini. Le nom définit le mode d’initialisation de l’essaim de particules pour l’algorithme « ParticleSwarmOptimization ». La série des particules est initialisée en spécifiant la distribution par composante, qui peut être identique pour toutes les composantes (c’est le cas pour toutes les valeurs sauf « DistributionByComponents »), ou spécifique par composante avec « DistributionByComponents ». Dans ce dernier cas, il faut par ailleurs spécifier le contenu du mot-clé « DistributionByComponents ». La valeur par défaut est « UniformByComponents ».
Le nom possible est donc dans la liste suivante : [« UniformByComponents », « LogUniformByComponents », « LogarithmicByComponents », « DistributionByComponents »].
Exemple :
{"SwarmInitialization":"UniformByComponents"}- StoreSupplementaryCalculations
Liste de noms. Cette liste indique les noms des variables supplémentaires, qui peuvent être disponibles au cours du déroulement ou à la fin de l’algorithme, si elles sont initialement demandées par l’utilisateur. Leur disponibilité implique, potentiellement, des calculs ou du stockage coûteux. La valeur par défaut est donc une liste vide, aucune de ces variables n’étant calculée et stockée par défaut (sauf les variables inconditionnelles). Les noms possibles pour les variables supplémentaires sont dans la liste suivante (la description détaillée de chaque variable nommée est donnée dans la suite de cette documentation par algorithme spécifique, dans la sous-partie « Informations et variables disponibles à la fin de l’algorithme ») : [ « Analysis », « APosterioriCorrelations », « APosterioriCovariance », « APosterioriStandardDeviations », « APosterioriVariances », « BMA », « CostFunctionJ », « CostFunctionJb », « CostFunctionJo », « CurrentIterationNumber », « CurrentState », « EnsembleOfStates », « EnsembleOfSimulations », « Innovation », « InternalCostFunctionJ », « InternalCostFunctionJb », « InternalCostFunctionJo », « OMA », « OMB », « SimulatedObservationAtBackground », « SimulatedObservationAtCurrentState », « SimulatedObservationAtOptimum », ].
Exemple :
{"StoreSupplementaryCalculations":["CurrentState", "Residu"]}
- SwarmTopology
Nom prédéfini. Cette clé indique la manière dont les particules (ou insectes) se communiquent des informations lors de l’évolution de l’essaim particulaire. La méthode la plus classique consiste à échanger des informations entre toutes les particules (nommée « gbest » ou « FullyConnectedNeighborhood »). Mais il est souvent plus efficace d’échanger des informations sur un voisinage réduit, comme dans la méthode classique « lbest » (ou « RingNeighborhoodWithRadius1 ») échangeant des informations avec les deux particules voisines dans l’ordre de numérotation (la précédente et la suivante), ou la méthode « RingNeighborhoodWithRadius2 » échangeant avec les 4 voisins (les deux précédents et les deux suivants). Une variante de voisinage réduit consiste à échanger avec 3 voisins (méthode « AdaptativeRandomWith3Neighbors ») ou 5 voisins (méthode « AdaptativeRandomWith5Neighbors ») choisis aléatoirement (la particule pouvant être tirée plusieurs fois). La valeur par défaut est « FullyConnectedNeighborhood », et il est conseillé de la changer avec prudence en fonction des propriétés du système physique simulé. La topologie de communication possible est à choisir dans la liste suivante, dans laquelle les noms équivalents sont indiqués par un signe « <=> » : [« FullyConnectedNeighborhood » <=> « FullyConnectedNeighbourhood » <=> « gbest », « RingNeighborhoodWithRadius1 » <=> « RingNeighbourhoodWithRadius1 » <=> « lbest », « RingNeighborhoodWithRadius2 » <=> « RingNeighbourhoodWithRadius2 », « AdaptativeRandomWith3Neighbors » <=> « AdaptativeRandomWith3Neighbours » <=> « abest », « AdaptativeRandomWith5Neighbors » <=> « AdaptativeRandomWith5Neighbours »].
Exemple :
{"SwarmTopology":"FullyConnectedNeighborhood"}
- Variant
Nom prédéfini. Cette clé permet de choisir l’une des variantes possibles pour l’algorithme principal. La variante par défaut est la formulation « CanonicalPSO » d’origine, et les choix possibles sont « CanonicalPSO » (Canonical Particle Swarm Optimization), « OGCR » (Simple Particle Swarm Optimization), « SPSO-2011 » (Standard Standard Particle Swarm Optimization 2011) identique à « SPSO-2011-AIS » (Standard Standard Particle Swarm Optimisation 2011 with Asynchronous Iteration Strategy), « SPSO-2011-SIS » (Standard Particle Swarm Optimisation 2011 with Synchronous Iteration Strategy), « SPSO-2011-PSIS » (Standard Particle Swarm Optimisation 2011 with Parallel Synchronous Iteration Strategy). Les versions avec accélération locale de type « VLS » (Variational Local Search) sont obtenues en ajoutant le suffixe « -VLS » à chaque méthode : « CanonicalPSO-VLS », « OGCR-VLS », « SPSO-2011-AIS-VLS », « SPSO-2011-SIS-VLS », « SPSO-2011-PSIS-VLS ».
Il est conseillé d’essayer la variante « CanonicalPSO » avec une centaine de particules pour une performance robuste, et de réduire le nombre de particules à une quarantaine pour toutes les variantes autres que la formulation « CanonicalPSO » originale.
Exemple :
{"Variant":"CanonicalPSO"}
- VelocityClampingFactor
Valeur réelle. Cette clé indique le taux d’atténuation de la vitesse de groupe dans la mise à jour pour chaque insecte, utile pour éviter l’explosion de l’essaim, c’est-à-dire une croissance incontrôlée de la vitesse des insectes. C’est une valeur réelle comprise entre 0+ et 1. Le défaut est de 0.3.
Exemple :
{"VelocityClampingFactor":0.3}
13.13.4. Informations et variables disponibles à la fin de l’algorithme¶
En sortie, après exécution de l’algorithme, on dispose d’informations et de
variables issues du calcul. La description des
Variables et informations disponibles en sortie indique la manière de les obtenir, par la
méthode nommée get, depuis la variable « ADD » du post-processing en
interface graphique, ou depuis le cas en interface textuelle. Les variables
d’entrée, mises à disposition de l’utilisateur en sortie pour faciliter
l’écriture des procédures de post-processing, sont décrites dans un
Inventaire des informations potentiellement disponibles en sortie.
Sorties permanentes (non conditionnelles)
Les sorties non conditionnelles de l’algorithme sont les suivantes :
- Analysis
Liste de vecteurs. Chaque élément de cette variable est un état optimal
 en optimisation, une interpolation ou une analyse
en optimisation, une interpolation ou une analyse
 en assimilation de données.
en assimilation de données.Exemple :
xa = ADD.get("Analysis")[-1]
- CostFunctionJ
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
choisie.Exemple :
J = ADD.get("CostFunctionJ")[:]
- CostFunctionJb
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
 , c’est-à-dire de la partie écart à l’ébauche. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.
, c’est-à-dire de la partie écart à l’ébauche. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.Exemple :
Jb = ADD.get("CostFunctionJb")[:]
- CostFunctionJo
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
 , c’est-à-dire de la partie écart à l’observation.
, c’est-à-dire de la partie écart à l’observation.Exemple :
Jo = ADD.get("CostFunctionJo")[:]
Ensemble des sorties à la demande (conditionnelles ou non)
L’ensemble des sorties (conditionnelles ou non) de l’algorithme, classées par ordre alphabétique, est le suivant :
- Analysis
Liste de vecteurs. Chaque élément de cette variable est un état optimal
en optimisation, une interpolation ou une analyse
en assimilation de données.Exemple :
xa = ADD.get("Analysis")[-1]
- APosterioriCorrelations
Liste de matrices. Chaque élément est une matrice de corrélations des erreurs a posteriori de l’état optimal, issue de la matrice
 des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.
des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.Exemple :
apc = ADD.get("APosterioriCorrelations")[-1]
- APosterioriCovariance
Liste de matrices. Chaque élément est une matrice
de
covariances des erreurs a posteriori de l’état optimal.Exemple :
apc = ADD.get("APosterioriCovariance")[-1]
- APosterioriStandardDeviations
Liste de matrices. Chaque élément est une matrice diagonale d’écarts-types des erreurs a posteriori de l’état optimal, issue de la matrice
des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.Exemple :
aps = ADD.get("APosterioriStandardDeviations")[-1]
- APosterioriVariances
Liste de matrices. Chaque élément est une matrice diagonale de variances des erreurs a posteriori de l’état optimal, issue de la matrice
des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.Exemple :
apv = ADD.get("APosterioriVariances")[-1]
- BMA
Liste de vecteurs. Chaque élément est un vecteur d’écart entre l’ébauche et l’état optimal.
Exemple :
bma = ADD.get("BMA")[-1]
- CostFunctionJ
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
choisie.Exemple :
J = ADD.get("CostFunctionJ")[:]
- CostFunctionJb
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
, c’est-à-dire de la partie écart à l’ébauche. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.Exemple :
Jb = ADD.get("CostFunctionJb")[:]
- CostFunctionJo
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
, c’est-à-dire de la partie écart à l’observation.Exemple :
Jo = ADD.get("CostFunctionJo")[:]
- CurrentIterationNumber
Liste d’entiers. Chaque élément est l’index d’itération courant au cours du déroulement itératif de l’algorithme utilisé. Il y a une valeur d’index d’itération par pas d’assimilation correspondant à un état observé.
Exemple :
cin = ADD.get("CurrentIterationNumber")[-1]
- CurrentState
Liste de vecteurs. Chaque élément est un vecteur d’état courant utilisé au cours du déroulement itératif de l’algorithme utilisé.
Exemple :
xs = ADD.get("CurrentState")[:]
- EnsembleOfStates
Liste de vecteurs ou matrice. Chaque élément est une collection ordonnée de vecteurs d’état physique ou d’état paramétrique
. Ce sont
des entrées d’opérateur , c’est-à-dire des états courants avant
observation. A chaque index de pas, il y a 1 état par colonne si cette liste
est sous forme matricielle, ou 1 état par élément si c’est effectivement une
liste. Important : la numérotation du support ou des points, sur lequel ou
auxquels sont fournis une valeur d’état dans chaque vecteur, est
implicitement celle de l’ordre naturel de numérotation du vecteur d’état, de
0 à la « taille moins 1 » de ce vecteur.Exemple :
{"EnsembleOfStates":[x1, x2, x3...]}
- EnsembleOfSimulations
Liste de vecteurs ou matrice. Chaque élément est une collection ordonnée de vecteurs d’état physique ou d’état simulé éventuellement observé
. Ce sont des sorties d’opérateur ,
c’est-à-dire des états d’observation simulés (nommés « snapshots » en
terminologie de bases réduites). A chaque index de pas, il y a 1 état par
colonne si cette liste est sous forme matricielle, ou 1 état par élément si
c’est effectivement une liste. Important : la numérotation du support ou des
points, sur lequel ou auxquels sont fournis une valeur d’état dans chaque
vecteur, est implicitement celle de l’ordre naturel de numérotation du
vecteur d’état, de 0 à la « taille moins 1 » de ce vecteur.Exemple :
{"EnsembleOfSimulations":[y1, y2, y3...]}
- Innovation
Liste de vecteurs. Chaque élément est un vecteur d’innovation, qui est en statique l’écart de l’optimum à l’ébauche, et en dynamique l’incrément d’évolution.
Exemple :
d = ADD.get("Innovation")[-1]
- OMA
Liste de vecteurs. Chaque élément est un vecteur d’écart entre l’observation et l’état optimal dans l’espace des observations.
Exemple :
oma = ADD.get("OMA")[-1]
- OMB
Liste de vecteurs. Chaque élément est un vecteur d’écart entre l’observation et l’état d’ébauche dans l’espace des observations.
Exemple :
omb = ADD.get("OMB")[-1]
- SimulatedObservationAtBackground
Liste de vecteurs. Chaque élément est un vecteur d’observation simulé par l’opérateur d’observation à partir de l’ébauche
. C’est
la prévision à partir de l’ébauche, elle est parfois appelée « Dry ».Exemple :
hxb = ADD.get("SimulatedObservationAtBackground")[-1]
- SimulatedObservationAtCurrentState
Liste de vecteurs. Chaque élément est un vecteur d’observation simulé par l’opérateur d’observation à partir de l’état courant, c’est-à-dire dans l’espace des observations.
Exemple :
hxs = ADD.get("SimulatedObservationAtCurrentState")[-1]
- SimulatedObservationAtOptimum
Liste de vecteurs. Chaque élément est un vecteur d’observation obtenu par l’opérateur d’observation à partir de la simulation d’analyse ou d’état optimal
. C’est l’observation de la prévision à partir de
l’analyse ou de l’état optimal, et elle est parfois appelée « Forecast ».Exemple :
hxa = ADD.get("SimulatedObservationAtOptimum")[-1]
13.13.5. Exemples d’utilisation en Python (TUI)¶
Voici un ou des exemples très simple d’usage de l’algorithme proposé et de ses paramètres, écrit en [DocR] Interface textuelle pour l’utilisateur (TUI/API). De plus, lorsque c’est possible, les informations indiquées en entrée permettent aussi de définir un cas équivalent en interface graphique [DocR] Interface graphique pour l’utilisateur (GUI/EFICAS).
Cet exemple décrit le recalage des paramètres d’un modèle
d’observation quadratique. Ce modèle est représenté ici comme une
fonction nommée QuadFunction. Cette fonction accepte en entrée le vecteur
de coefficients , et fournit en sortie le vecteur
d’évaluation du modèle quadratique aux points de contrôle
internes prédéfinis dans le modèle. Le calage s’effectue sur la base d’un jeu
initial de coefficients (état d’ébauche désigné par Xb dans l’exemple), et
avec l’information (désignée par Yobs dans l’exemple)
de 5 mesures obtenues à ces mêmes points de contrôle internes. On se place en
expériences jumelles (voir Pour tester une chaîne d’assimilation de données : les expériences jumelles) et les mesures sont
parfaites. On privilégie les observations au détriment de l’ébauche par
l’indication d’une très importante variance d’erreur d’ébauche, ici de
 .
.
L’ajustement s’effectue en affichant des résultats intermédiaires lors de l’optimisation itérative.
# -*- coding: utf-8 -*-
#
from numpy import array, ravel
def QuadFunction( coefficients ):
"""
Simulation quadratique aux points x : y = a x^2 + b x + c
"""
a, b, c = list(ravel(coefficients))
x_points = (-5, 0, 1, 3, 10)
y_points = []
for x in x_points:
y_points.append( a*x*x + b*x + c )
return array(y_points)
#
Xb = array([1., 1., 1.])
Yobs = array([57, 2, 3, 17, 192])
#
NumberOfInsects = 40
#
print("Résolution du problème de calage")
print("--------------------------------")
print("")
from adao import adaoBuilder
case = adaoBuilder.New()
case.setBackground( Vector = Xb, Stored=True )
case.setBackgroundError( ScalarSparseMatrix = 1.e6 )
case.setObservation( Vector = Yobs, Stored=True )
case.setObservationError( ScalarSparseMatrix = 1. )
case.setObservationOperator( OneFunction = QuadFunction )
case.setAlgorithmParameters(
Algorithm="ParticleSwarmOptimization",
Parameters={
"NumberOfInsects":NumberOfInsects,
"MaximumNumberOfIterations": 20,
"StoreSupplementaryCalculations": [
"CurrentState",
],
"Bounds":[[0,5],[-2,2],[0,5]],
"SetSeed":123456789,
},
)
case.setObserver(
Info=" État intermédiaire en itération courante :",
Template="ValuePrinter",
Variable="CurrentState",
)
case.execute()
print("")
#
#-------------------------------------------------------------------------------
#
print("Calage de %i coefficients pour une forme quadratique 1D sur %i mesures"%(
len(case.get("Background")),
len(case.get("Observation")),
))
print("--------------------------------------------------------------------")
print("")
print("Vecteur d'observation.............:", ravel(case.get("Observation")))
print("État d'ébauche a priori...........:", ravel(case.get("Background")))
print("")
print("Coefficients théoriques attendus..:", ravel((2,-1,2)))
print("")
print("Nombre d'itérations...............:", len(case.get("CurrentState")))
print("Nombre de simulations.............:", NumberOfInsects*len(case.get("CurrentState")))
print("Coefficients résultants du calage.:", ravel(case.get("Analysis")[-1]))
#
Xa = case.get("Analysis")[-1]
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (10, 4)
#
plt.figure()
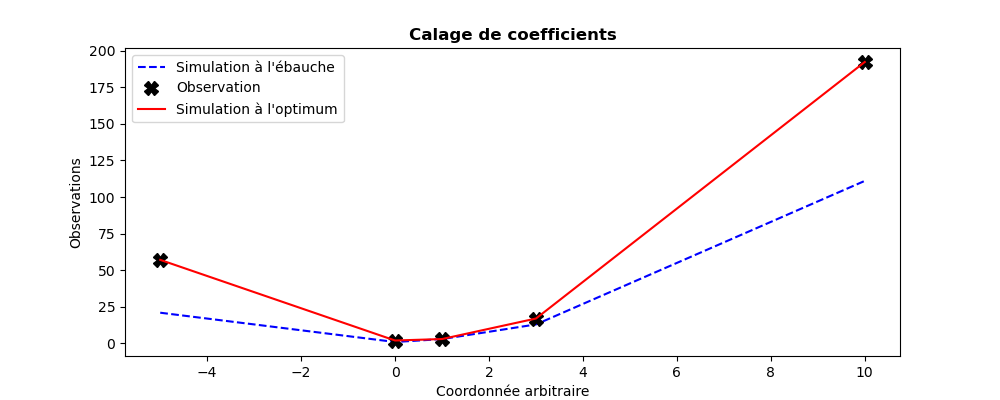
plt.plot((-5,0,1,3,10),QuadFunction(Xb),"b--",label="Simulation à l'ébauche")
plt.plot((-5,0,1,3,10),Yobs, "kX", label="Observation",markersize=10)
plt.plot((-5,0,1,3,10),QuadFunction(Xa),"r-", label="Simulation à l'optimum")
plt.legend()
plt.title("Calage de coefficients", fontweight="bold")
plt.xlabel("Coordonnée arbitraire")
plt.ylabel("Observations")
plt.savefig("simple_ParticleSwarmOptimization1.png")
Le résultat de son exécution est le suivant :
Résolution du problème de calage
--------------------------------
État intermédiaire en itération courante : [ 1.76770856 -1.2054263 1.22625259]
État intermédiaire en itération courante : [ 2.04776518 -1.17449716 3.14493347]
État intermédiaire en itération courante : [ 2.04776518 -1.17449716 3.14493347]
État intermédiaire en itération courante : [ 2.01933291 -1. 3.15162067]
État intermédiaire en itération courante : [ 1.96384202 -0.74855119 3.40642058]
État intermédiaire en itération courante : [ 1.96384202 -0.74855119 3.40642058]
État intermédiaire en itération courante : [ 1.96384202 -0.74855119 3.40642058]
État intermédiaire en itération courante : [ 1.96384202 -0.74855119 3.40642058]
État intermédiaire en itération courante : [ 1.95417745 -0.73191939 3.14451887]
État intermédiaire en itération courante : [ 1.96217646 -0.7883895 2.91127919]
État intermédiaire en itération courante : [ 1.97610485 -1.00254825 2.89582746]
État intermédiaire en itération courante : [ 2.0007262 -1.06443275 2.69825603]
État intermédiaire en itération courante : [ 1.9934285 -1.02432071 2.39823319]
État intermédiaire en itération courante : [ 1.9934285 -1.02432071 2.39823319]
État intermédiaire en itération courante : [ 1.9942533 -0.99256953 2.30174702]
État intermédiaire en itération courante : [ 1.9942533 -0.99256953 2.30174702]
État intermédiaire en itération courante : [ 1.99742923 -0.99796085 2.1278678 ]
État intermédiaire en itération courante : [ 1.99742923 -0.99796085 2.1278678 ]
État intermédiaire en itération courante : [ 1.99742923 -0.99796085 2.1278678 ]
État intermédiaire en itération courante : [ 1.99742923 -0.99796085 2.1278678 ]
État intermédiaire en itération courante : [ 2.00166149 -1.0012696 2.02137857]
Calage de 3 coefficients pour une forme quadratique 1D sur 5 mesures
--------------------------------------------------------------------
Vecteur d'observation.............: [ 57. 2. 3. 17. 192.]
État d'ébauche a priori...........: [1. 1. 1.]
Coefficients théoriques attendus..: [ 2 -1 2]
Nombre d'itérations...............: 21
Nombre de simulations.............: 840
Coefficients résultants du calage.: [ 2.00166149 -1.0012696 2.02137857]
Les graphiques illustrant le résultat de son exécution sont les suivants :