15.4. Algorithme de tâche « ParameterCalibrationTask »¶
15.4.1. Description¶
Cet algorithme permet d’établir le calage (ou le recalage) de paramètres d’un modèle, à partir d’observations ou de mesures et d’une idée a priori de ces paramètres.
Il permet d’agréger l’accès aux méthodes les plus utiles pour réaliser un tel calage. Il n’est pas destiné à remplacer les autres algorithmes d’assimilation de données ou d’optimisation décrits par ailleurs, mais à rendre plus rapide l’usage des algorithmes les plus simples et les plus performants pour le calage de paramètres. Il permet aussi, lorsque c’est nécessaire, d’initier un recalage avec les méthodes les plus classique, puis très simplement, en changeant d’algorithme, de passer à des méthodes spécifiques plus avancées ou plus adaptées aux particularités des problèmes à traiter.
Il y a principalement 4 classes de méthodes qui permettent de réaliser simplement un recalage de paramètres de modèle. On indique ici les conditions générale de choix, dont les détails sont disponibles dans chaque partie spécifique de la documentation par algorithme.
- Optimisation variationnelle de type 3DVARvariante « 3DVARGradientOptimization »
C’est une méthode de type gradient « 3DVAR », qui est très souvent la plus efficace à la fois en raison du faible nombre de calculs requis et de la grande précision obtenue. Elle nécessite à la fois une bonne régularité du modèle à recaler par rapport à ses paramètres, une bonne précision des simulations disponibles, et une bonne séparation d’éventuels minima équivalents. Cela étant, lorsqu’elle s’applique correctement, c’est la méthode la plus économique en évaluations du modèle et la plus précise pour ce nombre d’évaluations. C’est en particulier vrai lorsque le nombre de paramètres à optimiser augmente, nombre auquel la méthode est très peu sensible. Enfin, les réglages de la méthode sur un modèle particulier sont aisés et peu nécessaires pour disposer de sa performance. Pour les détails et l’association précise des options, on peut se reporter à la documentation spécifique pour un Algorithme de calcul « 3DVAR ».
- Estimation semi-linéaire de type BLUEvariante « ExtendedBlueOptimization »
C’est une méthode d’estimation « ExtendedBlue », de type BLUE (Best Linear Unbiased Estimator), qui inclue une évaluation non-linéaire du modèle à recaler. L’intérêt de cette méthode est d’être une estimation non itérative, donc très économique en nombre d’évaluations. De plus, il y a très peu de paramètres à régler pour utiliser cette méthode. Néanmoins, par nature, elle est usuellement moins précise et moins robuste aux erreurs provenant de l’aspect non linéaire du modèle utilisé. Pour les détails et l’association précise des options, on peut se reporter à la documentation spécifique pour un Algorithme de calcul « ExtendedBlue ».
- Optimisation sans dérivéesvariante « DerivativeFreeOptimization »
C’est une méthode d’optimisation qui n’utilise pas de dérivation du modèle à recaler, et qui procède par approximations de type simplexe ou autres. L’intérêt de cette méthode est de n’imposer aucun comportement particulier du modèle par rapport à ses paramètres. Mais elle nécessite souvent un nombre important d’évaluations du modèle pour construire en interne une approximation efficiente. De plus, elle est très sensible au nombre de paramètres à optimiser, et ne convient qu’en faible dimension. Le nombre d’évaluations nécessaire est souvent supérieur de plusieurs ordres de grandeurs aux autres méthodes. Enfin, le réglage des paramètres est délicat sur un modèle particulier à recaler. Pour les détails et l’association précise des options, on peut se reporter à la documentation spécifique pour un Algorithme de calcul « DerivativeFreeOptimization ».
- Optimisation par essaim particulaire, canoniquevariante « CanonicalParticuleSwarmOptimization »
C’est une méthode d’optimisation de type méta-heuristique, qui utilise un ensemble (nommé « essaim ») d’évaluations du modèle à recaler pour cartographier l’espace des états et trouver le meilleur. L’intérêt de cette méthode est d’être très peu sensible au nombre de paramètres à optimiser, et de rechercher si possible l’état optimal global, sachant que le réglage des paramètres est délicat sur un modèle particulier à recaler. Elle est souvent plus coûteuse d’un ou deux ordres de grandeur qu’une méthode variationnelle. Pour les détails et l’association précise des options, on peut se reporter à la documentation spécifique pour un Algorithme de calcul « ParticleSwarmOptimization ».
- Optimisation par essaim particulaire, accéléréevariante « VariationalParticuleSwarmOptimization »
C’est une méthode d’optimisation de type méta-heuristique complétée par une accélération de recherche locale de type variationnelle. Dans le cas où il est possible de l’appliquer, cela permet idéalement de disposer de la recherche globale de la méta-heuristique par essaim avec une accélération locale de type variationnel pour pallier à la difficulté de convergence locale de l’essaim. Cette méthode est plus économique que la précédente en nombre d’évaluations du modèle à recaler, mais elle est assez délicate à régler sur un modèle particulier donné. Pour les détails et l’association précise des options, on peut se reporter à la documentation spécifique pour un Algorithme de calcul « ParticleSwarmOptimization ».
On conseille donc de conserver la méthode d’optimisation variationnelle par défaut « 3DVARGradientOptimization » pour disposer de la meilleure performance possible, qui présente aussi le plus de facilité de réglage des paramètres de l’optimisation vis-à-vis du modèle à recaler.
15.4.2. Quelques propriétés notables des méthodes implémentées¶
Pour compléter la description on synthétise ici quelques propriétés notables, des méthodes de l’algorithme ou de leurs implémentations. Ces propriétés peuvent avoir une influence sur la manière de l’utiliser ou sur ses performances de calcul. Pour de plus amples renseignements, on se reportera aux références plus complètes indiquées à la fin du descriptif de cet algorithme.
Les méthodes proposées par cet algorithme présentent un parallélisme interne, et peuvent donc profiter de ressources informatiques de répartition de calculs. L’interaction potentielle, entre le parallélisme interne des méthodes, et le parallélisme éventuellement présent dans les opérateurs d’observation ou d’évolution intégrant les codes de l’utilisateur, doit donc être soigneusement réglée.
15.4.3. Commandes requises et optionnelles¶
Les commandes générales requises, disponibles en édition dans l’interface graphique ou textuelle, sont les suivantes :
- Background
Vecteur. La variable désigne le vecteur d’ébauche ou d’initialisation, usuellement noté
 . Sa valeur est définie comme un objet
de type « Vector » ou « VectorSerie ». Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est définie comme un objet
de type « Vector » ou « VectorSerie ». Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- BackgroundError
Matrice. La variable désigne la matrice de covariance des erreurs d’ébauche, usuellement notée
 . Sa valeur est définie comme
un objet de type « Matrix », de type « ScalarSparseMatrix », ou de type
« DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est définie comme
un objet de type « Matrix », de type « ScalarSparseMatrix », ou de type
« DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- EvolutionError
Matrice. La variable désigne la matrice de covariance des erreurs a priori d’évolution, usuellement notée
 . Sa valeur est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- EvolutionModel
Opérateur. La variable désigne l’opérateur d’évolution du modèle, usuellement noté
 , qui décrit un pas élémentaire d’évolution
dynamique ou itérative. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle
, qui décrit un pas élémentaire d’évolution
dynamique ou itérative. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle  est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire
est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire  .
.
- Observation
Liste de vecteurs. La variable désigne le vecteur d’observation utilisé en assimilation de données ou en optimisation, et usuellement noté
 . Sa valeur est définie comme un objet de type « Vector »
si c’est une unique observation (temporelle ou pas) ou « VectorSerie » si
c’est une succession d’observations. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Sa valeur est définie comme un objet de type « Vector »
si c’est une unique observation (temporelle ou pas) ou « VectorSerie » si
c’est une succession d’observations. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- ObservationError
Matrice. La variable désigne la matrice de covariance des erreurs a priori d’ébauche, usuellement notée
 . Cette matrice est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
. Cette matrice est
définie comme un objet de type « Matrix », de type « ScalarSparseMatrix », ou
de type « DiagonalSparseMatrix », comme décrit en détail dans la section
Conditions requises pour décrire des matrices de covariance. Sa disponibilité en sortie est
conditionnée par le booléen « Stored » associé en entrée.
- ObservationOperator
Opérateur. La variable désigne l’opérateur d’observation, usuellement noté
 , qui transforme les paramètres d’entrée
, qui transforme les paramètres d’entrée  en
résultats
en
résultats  qui sont à comparer aux observations
. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle
est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire .
qui sont à comparer aux observations
. Sa valeur est définie comme un objet de type
« Function » ou de type « Matrix ». Dans le cas du type « Function »,
différentes formes fonctionnelles peuvent être utilisées, comme décrit dans
la section Conditions requises pour les fonctions décrivant un opérateur. Si un contrôle
est inclus dans le modèle d’observation, l’opérateur doit être appliqué à une
paire .
Les commandes optionnelles générales, disponibles en édition dans l’interface graphique ou textuelle, sont indiquées dans la Liste des commandes et mots-clés pour un cas orienté tâche ou étude dédiée. De plus, les paramètres de la commande « AlgorithmParameters » permettent d’indiquer les options particulières, décrites ci-après, de l’algorithme. On se reportera à la Description des options d’un algorithme par « AlgorithmParameters » pour le bon usage de cette commande.
Les options sont les suivantes :
On note que l’ensemble des options disponibles de cette tâche sont décrites ici, mais que seules certaines sont actives pour un variant particulier. La documentation précise de chaque variant est donc aussi utile pour le bon usage de chacune des options ici présente.
- Bounds
Liste de paires de valeurs réelles. Cette clé permet de définir des paires de bornes supérieure et inférieure pour chaque variable d’état optimisée. Les bornes doivent être données par une liste de liste de paires de bornes inférieure/supérieure pour chaque variable, avec une valeur
Nonechaque fois qu’il n’y a pas de borne. Les bornes peuvent toujours être spécifiées, mais seuls les optimiseurs sous contraintes les prennent en compte. Si la liste est vide, cela équivaut à une absence de bornes.Exemple :
{"Bounds":[[2.,5.],[1.e-2,10.],[-30.,None],[None,None]]}
- CognitiveAcceleration
Valeur réelle. Cette clé indique le taux de rappel vers la meilleure valeur connue précédemment de l’historique de l’insecte courant. C’est une valeur réelle positive. Le défaut est à peu près de
 et il
est recommandé de l’adapter, plutôt en le réduisant, au cas physique qui est
en traitement.
et il
est recommandé de l’adapter, plutôt en le réduisant, au cas physique qui est
en traitement.Dans le cas standard (non-adaptatif), ce taux est constant et vaut la valeur indiquée. Dans le cas adaptatif ASAPSO [Wang09], la valeur de cette clé indique le taux initial de rappel qui décroît ensuite linéairement selon le nombre de générations et le facteur associé « CognitiveAccelerationControl ».
Exemple :
{"CognitiveAcceleration":1.19315}
- CognitiveAccelerationControl
Valeur réelle. Cette clé indique le facteur de changement dans le taux de rappel vers la meilleure valeur connue précédemment de l’historique de l’insecte courant. C’est une valeur réelle positive dont le défaut est 0, c’est-à-dire que, par défaut, il n’y a aucun changement du taux de rappel.
Dans le cas adaptatif ASAPSO [Wang09], la valeur de cette clé indique le facteur de décroissance linéaire du taux de rappel avec le nombre de générations (rapporté au nombre total demandé de générations), sachant que la valeur initiale du taux est indiquée par le facteur associé « CognitiveAcceleration ». Il n’y a pas de valeur recommandée, mais on peut par exemple utiliser la valeur initiale
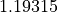 du facteur associé si
l’on veut annuler tout rappel vers la meilleure valeur connue de l’historique
à la fin des itérations.
du facteur associé si
l’on veut annuler tout rappel vers la meilleure valeur connue de l’historique
à la fin des itérations.Exemple :
{"CognitiveAccelerationControl":0.}
- CostDecrementTolerance
Valeur réelle. Cette clé indique une valeur limite, conduisant à arrêter le processus itératif d’optimisation lorsque la fonction coût décroît moins que cette tolérance au dernier pas. La valeur par défaut est de 1.e-7, et il est recommandé de l’adapter aux besoins pour des problèmes réels. On peut se reporter à la partie décrivant les manières de Contrôler la convergence pour des cas de calculs et algorithmes itératifs pour des recommandations plus détaillées.
Exemple :
{"CostDecrementTolerance":1.e-7}
- DistributionByComponents
Liste de noms prédéfinis. Ce mot-clé n’a besoin d’être défini que lorsque l’initialisation de l’essaim de particules pour l’algorithme « ParticleSwarmOptimization » est fixée à « DistributionByComponents ». Dans ce cas, il faut indiquer, pour chaque composante de l’état, la distribution choisie sous la forme d’un nom prédéfini. Les noms possibles sont « uniform », « loguniform », « logarithmic », « [“normal”,σ] », « [“lognormal”,σ] » et « [“logarithmicnormal”,σ] ». Toutes les distributions « normal » doivent être accompagnées d’une indication d’écart-type σ, sachant qu’elles sont centrées dans le domaine de définition. Les valeurs « uniform », « loguniform », « normal », « lognormal » n’agissent que sur l’initialisation de la position en appliquant la distribution indiquée, les valeurs « logarithmic » et « logarithmicnormal » agissent à la fois sur l’initialisation de la position et celle du mouvement. Il doit y en avoir le même nombre de valeurs indiquées que la taille d’un état individuel. Les distributions se conforment aux bornes indiquées pour l’algorithme « *ParticleSwarmOptimization ». Les distributions peuvent être différentes pour chaque axe. Lorsque l’on choisi une distribution identique pour toutes les composantes, cela équivaut à choisir à la place la valeur globale du mot-clé précédent s’il existe.
Exemple :
{"DistributionByComponents" : ['uniform', 'loguniform', 'logarithmic', ['normal', 1]]}pour un espace d’état de dimension 4.
- GlobalCostReductionTolerance
Valeur réelle. Cette clé indique le facteur de réduction limite, conduisant à arrêter le processus itératif d’optimisation lorsque la fonction coût décroît au moins de cette tolérance sur l’ensemble de la recherche optimale. La valeur par défaut est de 1.e-16 (ce qui équivaut à une absence d’effet), et il est recommandé de l’adapter aux besoins pour des problèmes réels.
Exemple :
{"GlobalCostReductionTolerance":1.e-16}
- GradientNormTolerance
Valeur réelle. Cette clé indique une valeur limite, conduisant à arrêter le processus itératif d’optimisation lorsque la norme du gradient est en dessous de cette limite. C’est utilisé uniquement par les optimiseurs sans contraintes. Le défaut est 1.e-5 et il n’est pas recommandé de le changer.
Exemple :
{"GradientNormTolerance":1.e-5}
- HybridCostDecrementTolerance
Valeur réelle. Cette clé indique une valeur limite, conduisant à arrêter le processus itératif d’optimisation dans la partie variationnelle du couplage, lorsque la fonction coût décroît moins que cette tolérance au dernier pas. Le défaut est de 1.e-7, et il est recommandé de l’adapter aux besoins pour des problèmes réels. On peut se reporter à la partie décrivant les manières de Contrôler la convergence pour des cas de calculs et algorithmes itératifs pour des recommandations plus détaillées.
Exemple :
{"HybridCostDecrementTolerance":1.e-7}
- HybridMaximumNumberOfIterations
Valeur entière. Cette clé indique le nombre maximum d’itérations internes possibles en optimisation hybride, pour la partie variationnelle. Le défaut est 15000, qui est très similaire à une absence de limite sur les itérations. Il est ainsi recommandé d’adapter ce paramètre aux besoins pour des problèmes réels. Pour certains optimiseurs, le nombre de pas effectif d’arrêt peut être légèrement différent de la limite à cause d’exigences de contrôle interne de l’algorithme. On peut se reporter à la partie décrivant les manières de Contrôler la convergence pour des cas de calculs et algorithmes itératifs pour des recommandations plus détaillées.
Exemple :
{"HybridMaximumNumberOfIterations":100}
- HybridNumberOfLocalHunters
Valeur entière. Cette clé indique le nombre d’insectes sur lesquels la recherche locale va être conduite. Les insectes sont choisis comme les meilleurs de l’itération courante de la recherche globale. Avec une valeur par défaut de 1, la recherche locale est effectuée uniquement sur le meilleur. Il est ainsi recommandé d’adapter ce paramètre aux besoins pour des problèmes réels.
Exemple :
{"HybridNumberOfLocalHunters":1}
- HybridNumberOfWarmupIterations
Valeur entière. Cette clé indique le nombre d’itérations initiales de la recherche globale effectuées avant d’établir une recherche locale sur les meilleurs insectes. Par défaut avec une valeur de 0, la recherche locale est effectuée dès le premier pas itératif de la recherche globale.
Exemple :
{"HybridNumberOfWarmupIterations":0}
- InertiaWeight
Valeur réelle. Cette clé indique la part de la vitesse de l’essaim qui est imposée à l’insecte, dite « poids de l’inertie ». C’est une valeur réelle comprise entre 0 et 1. Le défaut est de à peu près
 et il
est recommandé de l’adapter au cas physique qui est en traitement.
et il
est recommandé de l’adapter au cas physique qui est en traitement.Exemple :
{"InertiaWeight":0.72135}
- InitializationPoint
Vecteur. La variable désigne un vecteur à utiliser comme l’état initial autour duquel démarre un algorithme itératif. Par défaut, cet état initial n’a pas besoin d’être fourni et il est égal à l’ébauche
.
Sa valeur doit permettre de construire un vecteur de taille identique à
l’ébauche. Dans le cas où il est fourni, il ne remplace l’ébauche que pour
l’initialisation.Exemple :
{"InitializationPoint":[1, 2, 3, 4, 5]}
- MaximumNumberOfFunctionEvaluations
Valeur entière. Cette clé indique le nombre maximum d’évaluations possibles de la fonctionnelle à optimiser. Le défaut est de 15000, qui est une limite arbitraire. Il est ainsi recommandé d’adapter ce paramètre aux besoins pour des problèmes réels. Pour certains optimiseurs, le nombre effectif d’évaluations à l’arrêt peut être légèrement différent de la limite à cause d’exigences de déroulement interne de l’algorithme.
Exemple :
{"MaximumNumberOfFunctionEvaluations":50}
- MaximumNumberOfIterations
Valeur entière. Cette clé indique le nombre maximum d’itérations internes possibles en optimisation itérative. Le défaut est 15000, qui est très similaire à une absence de limite sur ce nombre d’itérations. Il est ainsi recommandé d’adapter ce paramètre aux besoins pour des problèmes réels. Pour certains optimiseurs, le nombre de pas effectif d’arrêt peut être légèrement différent de la limite à cause d’exigences de contrôle interne de l’algorithme. On peut se reporter à la partie décrivant les manières de Contrôler la convergence pour des cas de calculs et algorithmes itératifs pour des recommandations plus détaillées.
Exemple :
{"MaximumNumberOfIterations":100}
- Minimizer
Nom prédéfini. Cette clé permet de changer le minimiseur pour l’optimiseur. Le choix par défaut est « LBFGSB », et les choix possibles sont les suivants pour les variants variationnels « LBFGSB » (minimisation non linéaire sous contraintes, voir [Byrd95], [Morales11], [Zhu97]), « BFGS » (minimisation non linéaire sans contraintes), et les suivants pour les variants sans dérivation « BOBYQA » (minimisation, avec ou sans contraintes, par approximation quadratique, voir [Powell09]), « COBYLA » (minimisation, avec ou sans contraintes, par approximation linéaire, voir [Powell94] [Powell98]). « NEWUOA » (minimisation, avec ou sans contraintes, par approximation quadratique itérative, voir [Powell04]), « POWELL » (minimisation, sans contraintes, de type directions conjuguées, voir [Powell64]), « SIMPLEX » (minimisation, avec ou sans contraintes, de type Nelder-Mead utilisant le concept de simplexe, voir [Nelder65] et [WikipediaNM]), « SUBPLEX » (minimisation, avec ou sans contraintes, de type Nelder-Mead utilisant le concept de simplexe sur une suite de sous-espaces, voir [Rowan90]). Seul le minimiseur « POWELL » ne permet pas de traiter les contraintes de bornes, tous les autres en tiennent compte si elles sont présentes dans la définition du cas.
Exemple :
{"Minimizer":"LBFGSB"}
- NumberOfInsects
Valeur entière. Cette clé indique le nombre d’insectes ou de particules dans l’essaim. La valeur par défaut est 100, qui est une valeur par défaut usuelle pour cet algorithme.
Exemple :
{"NumberOfInsects":100}
- NumberOfSamplesForQuantiles
Valeur entière. Cette clé indique le nombre de simulations effectuées pour estimer les quantiles. Cette option n’est utile que si le calcul supplémentaire « SimulationQuantiles » a été choisi. Le défaut est 100, ce qui suffit souvent pour une estimation correcte de quantiles courants à 5%, 10%, 90% ou 95%.
Exemple :
{"NumberOfSamplesForQuantiles":100}
- ProjectedGradientTolerance
Valeur réelle. Cette clé indique une valeur limite, conduisant à arrêter le processus itératif d’optimisation lorsque toutes les composantes du gradient projeté sont en-dessous de cette limite. C’est utilisé uniquement par les optimiseurs sous contraintes. Le défaut est -1, qui désigne le défaut interne de chaque optimiseur (usuellement 1.e-5), et il n’est pas recommandé de le changer.
Exemple :
{"ProjectedGradientTolerance":-1}
- QualityCriterion
Nom prédéfini. Cette clé indique le critère de qualité, qui est minimisé pour trouver l’estimation optimale de l’état. Le défaut est le critère usuel de l’assimilation de données nommé « DA », qui est le critère de moindres carrés pondérés augmentés. Le critère possible est dans la liste suivante, dans laquelle les noms équivalents sont indiqués par un signe « <=> » : [« AugmentedWeightedLeastSquares » <=> « AWLS » <=> « DA », « WeightedLeastSquares » <=> « WLS », « LeastSquares » <=> « LS » <=> « L2 », « AbsoluteValue » <=> « L1 », « MaximumError » <=> « ME » <=> « Linf »]. On pourra se reporter à la section pour Approfondir l’estimation d’état par des méthodes d’optimisation afin de disposer de la définition détaillée de ces critères de qualité.
Exemple :
{"QualityCriterion":"DA"}
- Quantiles
Liste de valeurs réelles. Cette liste indique les valeurs de quantile, entre 0 et 1, à estimer par simulation autour de l’état optimal. L’échantillonnage utilise des tirages aléatoires gaussiens multivariés, dirigés par la matrice de covariance a posteriori. Cette option n’est utile que si le calcul supplémentaire « SimulationQuantiles » a été choisi. La valeur par défaut est une liste vide.
Exemple :
{"Quantiles":[0.1,0.9]}
- SetSeed
Valeur entière. Cette clé permet de donner un nombre entier pour fixer la graine du générateur aléatoire utilisé dans l’algorithme. Par défaut, la graine est laissée non initialisée, et elle utilise ainsi l’initialisation par défaut de l’ordinateur, qui varie donc à chaque étude. Pour assurer la reproductibilité de résultats impliquant des tirages aléatoires, il est fortement conseillé d’initialiser la graine. Une valeur simple est par exemple 123456789. Il est conseillé de mettre un entier à plus de 6 ou 7 chiffres pour bien initialiser le générateur aléatoire.
Exemple :
{"SetSeed":123456789}
- SimulationForQuantiles
Nom prédéfini. Cette clé indique le type de simulation, linéaire (avec l’opérateur d’observation tangent appliqué sur des incréments de perturbations autour de l’état optimal) ou non-linéaire (avec l’opérateur d’observation standard appliqué aux états perturbés), que l’on veut faire pour chaque perturbation. Cela change essentiellement le temps de chaque simulation élémentaire, usuellement plus long en non-linéaire qu’en linéaire. Cette option n’est utile que si le calcul supplémentaire « SimulationQuantiles » a été choisi. La valeur par défaut est « Linear », et les choix possibles sont « Linear » et « NonLinear ».
Exemple :
{"SimulationForQuantiles":"Linear"}
- SocialAcceleration
Valeur réelle. Cette clé indique le taux de rappel vers le meilleur insecte du voisinage de l’insecte courant, qui est par défaut l’essaim complet. C’est une valeur réelle positive. Le défaut est à peu près de
et il est recommandé de l’adapter, plutôt en le
réduisant, au cas physique qui est en traitement.Dans le cas standard (non-adaptatif), ce taux est constant et vaut la valeur indiquée. Dans le cas adaptatif ASAPSO [Wang09], la valeur de cette clé indique le taux initial de rappel qui croît ensuite linéairement selon le nombre de générations et le facteur associé « SocialAccelerationControl ».
Exemple :
{"SocialAcceleration":1.19315}
- SocialAccelerationControl
Valeur réelle. Cette clé indique le facteur de changement dans le taux de rappel vers le meilleur insecte du voisinage de l’insecte courant, qui est par défaut l’essaim complet. C’est une valeur réelle positive dont le défaut est 0, c’est-à-dire que, par défaut, il n’y a aucun changement du taux de rappel.
Dans le cas adaptatif ASAPSO [Wang09], la valeur de cette clé indique le facteur de croissance linéaire du taux de rappel avec le nombre de générations (rapporté au nombre total demandé de générations), sachant que la valeur initiale du taux est indiquée par le facteur associé « SocialAcceleration ». Il n’y a pas de valeur recommandée, mais on peut par exemple utiliser la valeur initiale
du facteur associé si
l’on veut doubler le rappel vers la meilleure valeur connue du voisinage à la
fin des itérations.Exemple :
{"SocialAccelerationControl":0.}
- StateBoundsForQuantiles
Liste de paires de valeurs réelles. Cette clé permet de définir des paires de bornes supérieure et inférieure pour chaque variable d’état utilisée dans la simulation des quantiles. Les bornes doivent être données par une liste de liste de paires de bornes inférieure/supérieure pour chaque variable, avec une valeur
Nonechaque fois qu’il n’y a pas de borne.En l’absence de définition de ces bornes pour la simulation des quantiles et si des bornes d’optimisation sont définies, ce sont ces dernières qui sont utilisées pour la simulation des quantiles. Si ces bornes pour la simulation des quantiles sont définies, elles sont utilisées quelles que soient les bornes d’optimisation définies. Si cette variable est définie à
None, alors aucune borne n’est utilisée pour les états utilisés dans la simulation des quantiles quelles que soient les bornes d’optimisation définies.Exemple :
{"StateBoundsForQuantiles":[[2.,5.],[1.e-2,10.],[-30.,None],[None,None]]}
- StateVariationTolerance
Valeur réelle. Cette clé indique la variation relative maximale de l’état lors de l’arrêt par convergence sur l’état. Le défaut est de 1.e-4, et il est recommandé de l’adapter aux besoins pour des problèmes réels.
Exemple :
{"StateVariationTolerance":1.e-4}- StoreSupplementaryCalculations
Liste de noms. Cette liste indique les noms des variables supplémentaires, qui peuvent être disponibles au cours du déroulement ou à la fin de l’algorithme, si elles sont initialement demandées par l’utilisateur. Leur disponibilité implique, potentiellement, des calculs ou du stockage coûteux. La valeur par défaut est donc une liste vide, aucune de ces variables n’étant calculée et stockée par défaut (sauf les variables inconditionnelles). Les noms possibles pour les variables supplémentaires sont dans la liste suivante (la description détaillée de chaque variable nommée est donnée dans la suite de cette documentation par algorithme spécifique, dans la sous-partie « Informations et variables disponibles à la fin de l’algorithme ») : [ « Analysis », « APosterioriCorrelations », « APosterioriCovariance », « APosterioriStandardDeviations », « APosterioriVariances », « BMA », « CostFunctionJ », « CostFunctionJAtCurrentOptimum », « CostFunctionJb », « CostFunctionJbAtCurrentOptimum », « CostFunctionJo », « CostFunctionJoAtCurrentOptimum », « CurrentIterationNumber », « CurrentOptimum », « CurrentState », « CurrentStepNumber », « EnsembleOfSimulations », « EnsembleOfStates », « ForecastState », « IndexOfOptimum », « Innovation », « InnovationAtCurrentAnalysis », « InnovationAtCurrentState », « JacobianMatrixAtBackground », « JacobianMatrixAtOptimum », « KalmanGainAtOptimum », « MahalanobisConsistency », « OMA », « OMB », « SampledStateForQuantiles », « SigmaObs2 », « SimulatedObservationAtBackground », « SimulatedObservationAtCurrentOptimum », « SimulatedObservationAtCurrentState », « SimulatedObservationAtOptimum », « SimulationQuantiles », ].
Exemple :
{"StoreSupplementaryCalculations":["CurrentState", "Residu"]}
- SwarmInitialization
Nom prédéfini. Le nom définit le mode d’initialisation de l’essaim de particules pour l’algorithme « ParticleSwarmOptimization ». La série des particules est initialisée en spécifiant la distribution par composante, qui peut être identique pour toutes les composantes (c’est le cas pour toutes les valeurs sauf « DistributionByComponents »), ou spécifique par composante avec « DistributionByComponents ». Dans ce dernier cas, il faut par ailleurs spécifier le contenu du mot-clé « DistributionByComponents ». La valeur par défaut est « UniformByComponents ».
Le nom possible est donc dans la liste suivante : [« UniformByComponents », « LogUniformByComponents », « LogarithmicByComponents », « DistributionByComponents »].
Exemple :
{"SwarmInitialization":"UniformByComponents"}
- SwarmTopology
Nom prédéfini. Cette clé indique la manière dont les particules (ou insectes) se communiquent des informations lors de l’évolution de l’essaim particulaire. La méthode la plus classique consiste à échanger des informations entre toutes les particules (nommée « gbest » ou « FullyConnectedNeighborhood »). Mais il est souvent plus efficace d’échanger des informations sur un voisinage réduit, comme dans la méthode classique « lbest » (ou « RingNeighborhoodWithRadius1 ») échangeant des informations avec les deux particules voisines dans l’ordre de numérotation (la précédente et la suivante), ou la méthode « RingNeighborhoodWithRadius2 » échangeant avec les 4 voisins (les deux précédents et les deux suivants). Une variante de voisinage réduit consiste à échanger avec 3 voisins (méthode « AdaptativeRandomWith3Neighbors ») ou 5 voisins (méthode « AdaptativeRandomWith5Neighbors ») choisis aléatoirement (la particule pouvant être tirée plusieurs fois). La valeur par défaut est « FullyConnectedNeighborhood », et il est conseillé de la changer avec prudence en fonction des propriétés du système physique simulé. La topologie de communication possible est à choisir dans la liste suivante, dans laquelle les noms équivalents sont indiqués par un signe « <=> » : [« FullyConnectedNeighborhood » <=> « FullyConnectedNeighbourhood » <=> « gbest », « RingNeighborhoodWithRadius1 » <=> « RingNeighbourhoodWithRadius1 » <=> « lbest », « RingNeighborhoodWithRadius2 » <=> « RingNeighbourhoodWithRadius2 », « AdaptativeRandomWith3Neighbors » <=> « AdaptativeRandomWith3Neighbours » <=> « abest », « AdaptativeRandomWith5Neighbors » <=> « AdaptativeRandomWith5Neighbours »].
Exemple :
{"SwarmTopology":"FullyConnectedNeighborhood"}
- VelocityClampingFactor
Valeur réelle. Cette clé indique le taux d’atténuation de la vitesse de groupe dans la mise à jour pour chaque insecte, utile pour éviter l’explosion de l’essaim, c’est-à-dire une croissance incontrôlée de la vitesse des insectes. C’est une valeur réelle comprise entre 0+ et 1. Le défaut est de 0.3.
Exemple :
{"VelocityClampingFactor":0.3}
- Variant
Nom prédéfini. Cette clé permet de choisir l’une des variantes possibles pour l’algorithme principal de calage de paramètres. La variante par défaut est le « 3DVAR » d’origine, et les choix possibles sont « 3DVARGradientOptimization » ou « 3DVAR » (analyse variationnelle de type 3DVAR), « ExtendedBlueOptimization » ou « ExtendedBlue » (estimation semi-linéaire de type BLUE), « DerivativeFreeOptimization » ou « DFO » (optimisation sans dérivées par approximation de type simplexe ou autres), « CanonicalParticuleSwarmOptimization » ou « CanonicalPSO » ou « PSO » (optimisation canonique par essaim particulaire), « VariationalParticuleSwarmOptimization » ou « SPSO-2011-AIS-VLS » (optimisation standard 2011 par essaim particulaire, avec accélération par recherche variationnelle locale), Il est fortement recommandé de conserver la valeur par défaut.
Exemple :
{"Variant":"3DVAR"}
15.4.4. Informations et variables disponibles à la fin de l’algorithme¶
En sortie, après exécution de l’algorithme, on dispose d’informations et de
variables issues du calcul. La description des
Variables et informations disponibles en sortie indique la manière de les obtenir, par la
méthode nommée get, depuis la variable « ADD » du post-processing en
interface graphique, ou depuis le cas en interface textuelle. Les variables
d’entrée, mises à disposition de l’utilisateur en sortie pour faciliter
l’écriture des procédures de post-processing, sont décrites dans un
Inventaire des informations potentiellement disponibles en sortie.
Sorties permanentes (non conditionnelles)
Les sorties non conditionnelles de l’algorithme sont les suivantes :
- Analysis
Liste de vecteurs. Chaque élément de cette variable est un état optimal
 en optimisation, une interpolation ou une analyse
en optimisation, une interpolation ou une analyse
 en assimilation de données.
en assimilation de données.Exemple :
xa = ADD.get("Analysis")[-1]
- CostFunctionJ
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
 choisie.
choisie.Exemple :
J = ADD.get("CostFunctionJ")[:]
- CostFunctionJb
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
 , c’est-à-dire de la partie écart à l’ébauche. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.
, c’est-à-dire de la partie écart à l’ébauche. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.Exemple :
Jb = ADD.get("CostFunctionJb")[:]
- CostFunctionJo
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
 , c’est-à-dire de la partie écart à l’observation.
, c’est-à-dire de la partie écart à l’observation.Exemple :
Jo = ADD.get("CostFunctionJo")[:]
- CurrentState
Liste de vecteurs. Chaque élément est un vecteur d’état courant utilisé au cours du déroulement itératif de l’algorithme utilisé.
Exemple :
xs = ADD.get("CurrentState")[:]
Ensemble des sorties à la demande (conditionnelles ou non)
L’ensemble des sorties (conditionnelles ou non) de l’algorithme, classées par ordre alphabétique, est le suivant :
- Analysis
Liste de vecteurs. Chaque élément de cette variable est un état optimal
en optimisation, une interpolation ou une analyse
en assimilation de données.Exemple :
xa = ADD.get("Analysis")[-1]
- APosterioriCorrelations
Liste de matrices. Chaque élément est une matrice de corrélations des erreurs a posteriori de l’état optimal, issue de la matrice
 des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.
des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.Exemple :
apc = ADD.get("APosterioriCorrelations")[-1]
- APosterioriCovariance
Liste de matrices. Chaque élément est une matrice
de
covariances des erreurs a posteriori de l’état optimal.Exemple :
apc = ADD.get("APosterioriCovariance")[-1]
- APosterioriStandardDeviations
Liste de matrices. Chaque élément est une matrice diagonale d’écarts-types des erreurs a posteriori de l’état optimal, issue de la matrice
des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.Exemple :
aps = ADD.get("APosterioriStandardDeviations")[-1]
- APosterioriVariances
Liste de matrices. Chaque élément est une matrice diagonale de variances des erreurs a posteriori de l’état optimal, issue de la matrice
des covariances. Pour en disposer, il faut avoir en même
temps demandé le calcul de ces covariances d’erreurs a posteriori.Exemple :
apv = ADD.get("APosterioriVariances")[-1]
- BMA
Liste de vecteurs. Chaque élément est un vecteur d’écart entre l’ébauche et l’état optimal.
Exemple :
bma = ADD.get("BMA")[-1]
- CostFunctionJ
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
choisie.Exemple :
J = ADD.get("CostFunctionJ")[:]
- CostFunctionJAtCurrentOptimum
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
. A chaque pas, la valeur correspond à l’état optimal trouvé depuis
le début.Exemple :
JACO = ADD.get("CostFunctionJAtCurrentOptimum")[:]
- CostFunctionJb
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
, c’est-à-dire de la partie écart à l’ébauche. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.Exemple :
Jb = ADD.get("CostFunctionJb")[:]
- CostFunctionJbAtCurrentOptimum
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
, c’est-à-dire de la partie écart à l’ébauche. A chaque pas, la
valeur correspond à l’état optimal trouvé depuis le début. Si cette partie
n’existe pas dans la fonctionnelle, sa valeur est nulle.Exemple :
JbACO = ADD.get("CostFunctionJbAtCurrentOptimum")[:]
- CostFunctionJo
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
, c’est-à-dire de la partie écart à l’observation.Exemple :
Jo = ADD.get("CostFunctionJo")[:]
- CostFunctionJoAtCurrentOptimum
Liste de valeurs. Chaque élément est une valeur de fonctionnelle d’écart
, c’est-à-dire de la partie écart à l’observation. A chaque pas,
la valeur correspond à l’état optimal trouvé depuis le début.Exemple :
JoACO = ADD.get("CostFunctionJoAtCurrentOptimum")[:]
- CurrentIterationNumber
Liste d’entiers. Chaque élément est l’index d’itération courant au cours du déroulement itératif de l’algorithme utilisé. Il y a une valeur d’index d’itération par pas d’assimilation correspondant à un état observé.
Exemple :
cin = ADD.get("CurrentIterationNumber")[-1]
- CurrentOptimum
Liste de vecteurs. Chaque élément est le vecteur d’état optimal au pas de temps courant au cours du déroulement itératif de l’algorithme d’optimisation utilisé. Ce n’est pas nécessairement le dernier état.
Exemple :
xo = ADD.get("CurrentOptimum")[:]
- CurrentState
Liste de vecteurs. Chaque élément est un vecteur d’état courant utilisé au cours du déroulement itératif de l’algorithme utilisé.
Exemple :
xs = ADD.get("CurrentState")[:]
- CurrentStepNumber
Liste d’entiers. Chaque élément est l’index du pas courant au cours du déroulement itératif, piloté par la série des observations, de l’algorithme utilisé. Cela correspond au pas d’observation utilisé. Remarque : ce n’est pas l’index d’itération courant d’algorithme même si cela coïncide pour des algorithmes non itératifs.
Exemple :
csn = ADD.get("CurrentStepNumber")[-1]
- EnsembleOfSimulations
Liste de vecteurs ou matrice. Chaque élément est une collection ordonnée de vecteurs d’état physique ou d’état simulé éventuellement observé
. Ce sont des sorties d’opérateur ,
c’est-à-dire des états d’observation simulés (nommés « snapshots » en
terminologie de bases réduites). A chaque index de pas, il y a 1 état par
colonne si cette liste est sous forme matricielle, ou 1 état par élément si
c’est effectivement une liste. Important : la numérotation du support ou des
points, sur lequel ou auxquels sont fournis une valeur d’état dans chaque
vecteur, est implicitement celle de l’ordre naturel de numérotation du
vecteur d’état, de 0 à la « taille moins 1 » de ce vecteur.Exemple :
{"EnsembleOfSimulations":[y1, y2, y3...]}
- EnsembleOfStates
Liste de vecteurs ou matrice. Chaque élément est une collection ordonnée de vecteurs d’état physique ou d’état paramétrique
. Ce sont
des entrées d’opérateur , c’est-à-dire des états courants avant
observation. A chaque index de pas, il y a 1 état par colonne si cette liste
est sous forme matricielle, ou 1 état par élément si c’est effectivement une
liste. Important : la numérotation du support ou des points, sur lequel ou
auxquels sont fournis une valeur d’état dans chaque vecteur, est
implicitement celle de l’ordre naturel de numérotation du vecteur d’état, de
0 à la « taille moins 1 » de ce vecteur.Exemple :
{"EnsembleOfStates":[x1, x2, x3...]}
- ForecastState
Liste de vecteurs. Chaque élément est un vecteur d’état (ou un ensemble de vecteurs d’états selon l’algorithme) prévu(s) par le modèle au cours du déroulement itératif temporel de l’algorithme utilisé.
Exemple :
xf = ADD.get("ForecastState")[:]
- IndexOfOptimum
Liste d’entiers. Chaque élément est l’index d’itération de l’optimum obtenu au cours du déroulement itératif de l’algorithme d’optimisation utilisé. Ce n’est pas nécessairement le numéro de la dernière itération.
Exemple :
ioo = ADD.get("IndexOfOptimum")[-1]
- Innovation
Liste de vecteurs. Chaque élément est un vecteur d’innovation, qui est en statique l’écart de l’optimum à l’ébauche, et en dynamique l’incrément d’évolution.
Exemple :
d = ADD.get("Innovation")[-1]
- InnovationAtCurrentAnalysis
Liste de vecteurs. Chaque élément est un vecteur d’innovation à l’état analysé courant. Cette quantité est identique au vecteur d’innovation à l’état analysé dans le cas d’une assimilation mono-état.
Exemple :
da = ADD.get("InnovationAtCurrentAnalysis")[-1]
- InnovationAtCurrentState
Liste de vecteurs. Chaque élément est un vecteur d’innovation à l’état courant avant analyse.
Exemple :
ds = ADD.get("InnovationAtCurrentState")[-1]
- JacobianMatrixAtBackground
Liste de matrices. Chaque élément est une matrice jacobienne de dérivées partielles de la sortie de l’opérateur d’observation par rapport aux paramètres d’entrée, une colonne de dérivées par paramètre. Le calcul est effectué à l’état initial.
Exemple:
gradh = ADD.get("JacobianMatrixAtBackground")[-1]
- JacobianMatrixAtOptimum
Liste de matrices. Chaque élément est une matrice jacobienne de dérivées partielles de la sortie de l’opérateur d’observation par rapport aux paramètres d’entrée, une colonne de dérivées par paramètre. Le calcul est effectué à l’état optimal.
Exemple:
gradh = ADD.get("JacobianMatrixAtOptimum")[-1]
- KalmanGainAtOptimum
Liste de matrices. Chaque élément est une matrice de gain de Kalman standard, évaluée à l’aide de l’opérateur d’observation linéarisé. Le calcul est effectué à l’état optimal.
Exemple:
kg = ADD.get("KalmanGainAtOptimum")[-1]
- MahalanobisConsistency
Liste de valeurs. Chaque élément est une valeur de l’indicateur de qualité de Mahalanobis.
Exemple :
mc = ADD.get("MahalanobisConsistency")[-1]
- OMA
Liste de vecteurs. Chaque élément est un vecteur d’écart entre l’observation et l’état optimal dans l’espace des observations.
Exemple :
oma = ADD.get("OMA")[-1]
- OMB
Liste de vecteurs. Chaque élément est un vecteur d’écart entre l’observation et l’état d’ébauche dans l’espace des observations.
Exemple :
omb = ADD.get("OMB")[-1]
- SampledStateForQuantiles
Liste de séries de vecteurs. Chaque élément est une série de vecteurs d’état colonnes, généré pour estimer par simulation et/ou observation les valeurs de quantiles requis par l’utilisateur. Il y a autant d’états que le nombre d’échantillons requis pour cette estimation de quantiles.
Exemple :
xq = ADD.get("SampledStateForQuantiles")[:]
- SigmaObs2
Liste de valeurs. Chaque élément est une valeur de l’indicateur de qualité
 de la partie observation.
de la partie observation.Exemple :
so2 = ADD.get("SigmaObs")[-1]
- SimulatedObservationAtBackground
Liste de vecteurs. Chaque élément est un vecteur d’observation simulé par l’opérateur d’observation à partir de l’ébauche
. C’est
la prévision à partir de l’ébauche, elle est parfois appelée « Dry ».Exemple :
hxb = ADD.get("SimulatedObservationAtBackground")[-1]
- SimulatedObservationAtCurrentOptimum
Liste de vecteurs. Chaque élément est un vecteur d’observation simulé par l’opérateur d’observation à partir de l’état optimal au pas de temps courant au cours du déroulement de l’algorithme d’optimisation, c’est-à-dire dans l’espace des observations.
Exemple :
hxo = ADD.get("SimulatedObservationAtCurrentOptimum")[-1]
- SimulatedObservationAtCurrentState
Liste de vecteurs. Chaque élément est un vecteur d’observation simulé par l’opérateur d’observation à partir de l’état courant, c’est-à-dire dans l’espace des observations.
Exemple :
hxs = ADD.get("SimulatedObservationAtCurrentState")[-1]
- SimulatedObservationAtOptimum
Liste de vecteurs. Chaque élément est un vecteur d’observation obtenu par l’opérateur d’observation à partir de la simulation d’analyse ou d’état optimal
. C’est l’observation de la prévision à partir de
l’analyse ou de l’état optimal, et elle est parfois appelée « Forecast ».Exemple :
hxa = ADD.get("SimulatedObservationAtOptimum")[-1]
- SimulationQuantiles
Liste de séries de vecteurs. Chaque élément est une série de vecteurs colonnes d’observation, correspondant, pour un quantile particulier requis par l’utilisateur, à l’état observé qui réalise le quantile demandé. Chaque vecteur colonne d’observation est restitué dans le même ordre que les valeurs de quantiles requis par l’utilisateur.
Exemple :
sQuantiles = ADD.get("SimulationQuantiles")[:]
15.4.5. Exemples d’utilisation en Python (TUI)¶
Voici un ou des exemples très simple d’usage de l’algorithme proposé et de ses paramètres, écrit en [DocR] Interface textuelle pour l’utilisateur (TUI/API). De plus, lorsque c’est possible, les informations indiquées en entrée permettent aussi de définir un cas équivalent en interface graphique [DocR] Interface graphique pour l’utilisateur (GUI/EFICAS).
15.4.5.1. Premier exemple¶
Cet exemple décrit le recalage des paramètres d’un
modèle d’observation quadratique. Ce modèle est représenté
ici comme une fonction nommée QuadFunction pour les besoins de l’exemple.
Cette fonction accepte en entrée le vecteur de coefficients
de la forme quadratique, et fournit en sortie le vecteur
d’évaluation du modèle quadratique aux points de contrôle internes, prédéfinis
de manière statique dans le modèle.
Le recalage s’effectue sur la base d’un jeu initial de coefficients (état
d’ébauche désigné par Xb dans l’exemple), et avec l’information
(désignée par Yobs dans l’exemple) de 5 mesures
obtenues aux points de contrôle internes. On se place ici en expériences
jumelles (voir Pour tester une chaîne d’assimilation de données : les expériences jumelles), et les mesures sont
considérées comme parfaites. On choisit de privilégier les observations, au
détriment de l’ébauche, par l’indication artificielle d’une très importante
variance d’erreur d’ébauche, ici de  .
.
On utilise une optimisation variationnelle de type 3DVAR (méthode par défaut), explicitement demandée ici par la variante « 3DVARGradientOptimization » indiquée pour cet algorithme. On obtient par nature les mêmes résultats que dans le premier exemple de l’algorithme du « 3DVAR » (voir ses Exemples d’utilisation en Python (TUI)).
# -*- coding: utf-8 -*-
#
from numpy import array, ravel, abs, max, set_printoptions
set_printoptions(precision=7)
def QuadFunction( coefficients ):
"""
Simulation quadratique aux points x : y = a x^2 + b x + c
"""
a, b, c = list(ravel(coefficients))
x_points = (-5, 0, 1, 3, 10)
y_points = []
for x in x_points:
y_points.append( a*x*x + b*x + c )
return array(y_points)
#
Xb = array([1., 1., 1.])
Yobs = array([57, 2, 3, 17, 192])
#
from adao import adaoBuilder
case = adaoBuilder.New()
case.setBackground( Vector = Xb, Stored=True )
case.setBackgroundError( ScalarSparseMatrix = 1.e6 )
case.setObservation( Vector = Yobs, Stored=True )
case.setObservationError( ScalarSparseMatrix = 1. )
case.setObservationOperator( OneFunction = QuadFunction )
case.setAlgorithmParameters(
Algorithm="ParameterCalibrationTask",
Parameters={
"Variant":"3DVARGradientOptimization",
"Minimizer":"LBFGSB",
"MaximumNumberOfIterations": 100,
"StoreSupplementaryCalculations": [
"CurrentState",
"OMA",
],
},
)
case.execute()
#
#-------------------------------------------------------------------------------
#
print("Calage de %i coefficients pour une forme quadratique 1D sur %i mesures"%(
len(case.get("Background")),
len(case.get("Observation")),
))
print("--------------------------------------------------------------------")
print("")
print("Vecteur d'observation.............:", ravel(case.get("Observation")))
print("État d'ébauche a priori...........:", ravel(case.get("Background")))
print("")
print("Coefficients théoriques attendus..:", ravel((2,-1,2)))
print("")
print("Nombre de simulations.............:", len(case.get("CurrentState"))*4)
print("Écart maximum Observation-Analyse.:", "%.2e"%max(abs(ravel(case.get("OMA")[-1]))))
print("Coefficients résultants du calage.:", ravel(case.get("Analysis")[-1]))
#
Xa = case.get("Analysis")[-1]
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (10, 4)
#
plt.figure()
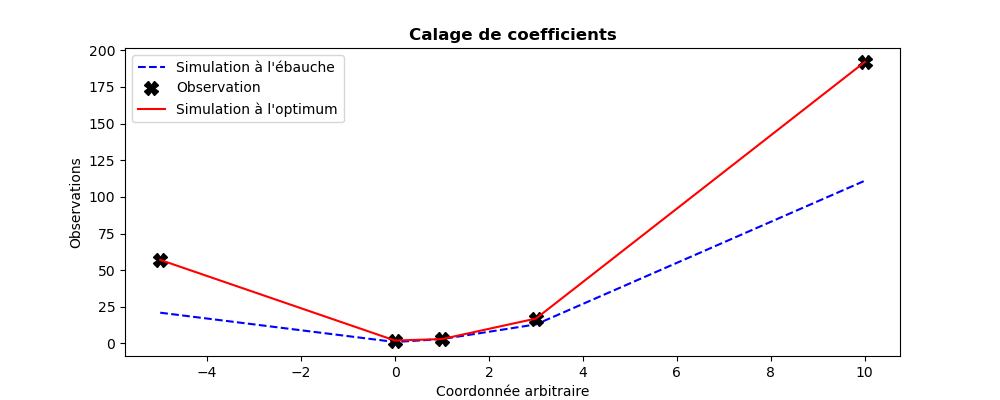
plt.plot((-5,0,1,3,10),QuadFunction(Xb),"b--",label="Simulation à l'ébauche")
plt.plot((-5,0,1,3,10),Yobs, "kX", label="Observation",markersize=10)
plt.plot((-5,0,1,3,10),QuadFunction(Xa),"r-", label="Simulation à l'optimum")
plt.legend()
plt.title("Calage de coefficients", fontweight="bold")
plt.xlabel("Coordonnée arbitraire")
plt.ylabel("Observations")
plt.savefig("simple_ParameterCalibrationTask1.png")
Le résultat de son exécution est le suivant :
Calage de 3 coefficients pour une forme quadratique 1D sur 5 mesures
--------------------------------------------------------------------
Vecteur d'observation.............: [ 57. 2. 3. 17. 192.]
État d'ébauche a priori...........: [1. 1. 1.]
Coefficients théoriques attendus..: [ 2 -1 2]
Nombre de simulations.............: 100
Écart maximum Observation-Analyse.: 5.83e-07
Coefficients résultants du calage.: [ 2. -0.9999999 1.9999999]
Les graphiques illustrant le résultat de son exécution sont les suivants :
15.4.5.2. Second exemple¶
Comme il est aisé de changer de méthode d’optimisation, l’objet de ce second exemple est de réaliser la calibration de paramètres à l’aide d’une optimisation sans dérivées. Elle est indiquée à cet algorithme par la variante « DerivativeFreeOptimization » (accompagnée d’un changement de l’optimiseur par le mot-clé « Minimizer »). Seuls les valeurs de ces deux mot-clés « Variant » et « Minimizer » changent donc entre les deux approches.
Dans ce cas extrêmement simple, de petite dimension et sans difficulté spéciale d’optimisation, les paramètres de contrôle restent les mêmes. Les résultats sont de la même qualité que pour l’optimisation variationnelle de référence.
# -*- coding: utf-8 -*-
#
from numpy import array, ravel, abs, max, set_printoptions
set_printoptions(precision=7)
def QuadFunction( coefficients ):
"""
Simulation quadratique aux points x : y = a x^2 + b x + c
"""
a, b, c = list(ravel(coefficients))
x_points = (-5, 0, 1, 3, 10)
y_points = []
for x in x_points:
y_points.append( a*x*x + b*x + c )
return array(y_points)
#
Xb = array([1., 1., 1.])
Yobs = array([57, 2, 3, 17, 192])
#
from adao import adaoBuilder
case = adaoBuilder.New()
case.setBackground( Vector = Xb, Stored=True )
case.setBackgroundError( ScalarSparseMatrix = 1.e6 )
case.setObservation( Vector = Yobs, Stored=True )
case.setObservationError( ScalarSparseMatrix = 1. )
case.setObservationOperator( OneFunction = QuadFunction )
case.setAlgorithmParameters(
Algorithm="ParameterCalibrationTask",
Parameters={
"Variant":"DerivativeFreeOptimization",
"Minimizer":"BOBYQA",
"MaximumNumberOfIterations": 100,
"StoreSupplementaryCalculations": [
"CurrentState",
"OMA",
],
},
)
case.execute()
#
#-------------------------------------------------------------------------------
#
print("Calage de %i coefficients pour une forme quadratique 1D sur %i mesures"%(
len(case.get("Background")),
len(case.get("Observation")),
))
print("--------------------------------------------------------------------")
print("")
print("Vecteur d'observation.............:", ravel(case.get("Observation")))
print("État d'ébauche a priori...........:", ravel(case.get("Background")))
print("")
print("Coefficients théoriques attendus..:", ravel((2,-1,2)))
print("")
print("Nombre de simulations.............:", len(case.get("CurrentState")))
print("Écart maximum Observation-Analyse.:", "%.2e"%max(abs(ravel(case.get("OMA")[-1]))))
print("Coefficients résultants du calage.:", ravel(case.get("Analysis")[-1]))
#
Xa = case.get("Analysis")[-1]
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (10, 4)
#
plt.figure()
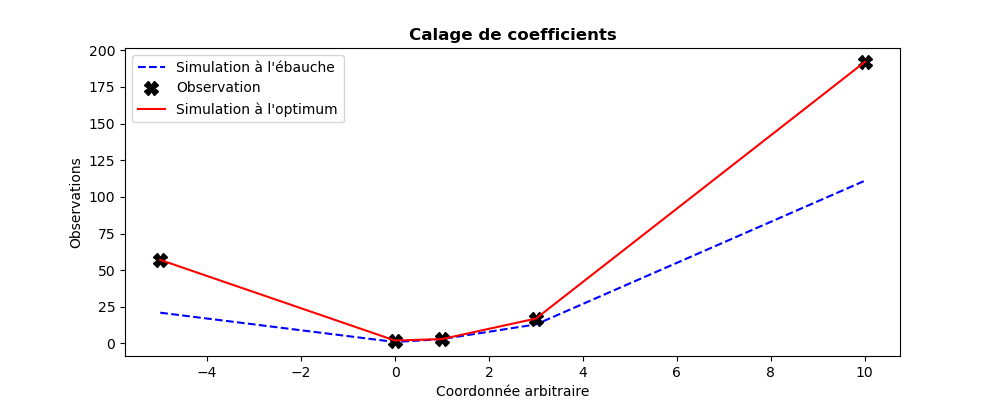
plt.plot((-5,0,1,3,10),QuadFunction(Xb),"b--",label="Simulation à l'ébauche")
plt.plot((-5,0,1,3,10),Yobs, "kX", label="Observation",markersize=10)
plt.plot((-5,0,1,3,10),QuadFunction(Xa),"r-", label="Simulation à l'optimum")
plt.legend()
plt.title("Calage de coefficients", fontweight="bold")
plt.xlabel("Coordonnée arbitraire")
plt.ylabel("Observations")
plt.savefig("simple_ParameterCalibrationTask2.png")
Le résultat de son exécution est le suivant :
Calage de 3 coefficients pour une forme quadratique 1D sur 5 mesures
--------------------------------------------------------------------
Vecteur d'observation.............: [ 57. 2. 3. 17. 192.]
État d'ébauche a priori...........: [1. 1. 1.]
Coefficients théoriques attendus..: [ 2 -1 2]
Nombre de simulations.............: 54
Écart maximum Observation-Analyse.: 6.09e-05
Coefficients résultants du calage.: [ 2.0000017 -1.0000109 1.9999648]
Les graphiques illustrant le résultat de son exécution sont les suivants :
15.4.6. Voir aussi¶
Références vers d’autres sections :